
作者:Duc-Vu Nguyen,Linh-Bao Vo,等
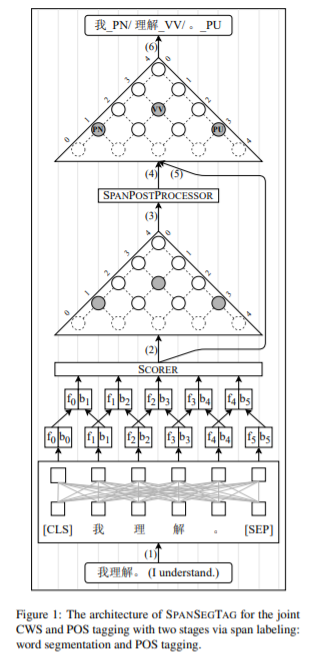
简介:越南对中文分词基于bert模型研究的新成果。中文分词和词性标注是计算语言学和自然语言处理应用中必不可少的任务。在深度学习时代,许多研究者仍在争论汉语分词和词性标注的需求。然而,解决歧义和检测未知词是这一领域的挑战性问题。以往对汉语分词和词性标注的联合研究主要遵循基于字符的标注模型,重点是对n-gram特征进行建模。与以前的工作不同,作者提出了SpanSegTag神经模型---用于汉语分词和词性标注,其中每个n-gram作为单词和词性标注的概率是主要问题。在连续字符的左右边界表示上,作者使用biaffine操作来建模n-gram。作者的实验表明:基于BERT的模型SpanSegTag在CTB5、CTB6和UD上取得了具有竞争力的性能,同时与当前使用BERT或ZEN编码器的最先进方法相比,在CTB7和CTB9基准数据集上取得了显著的改进。
论文下载:https://arxiv.org/pdf/2112.09488.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢