
关系抽取作为自然语言处理领域的一项重要的基础性任务,旨在从非结构化或半结构化文档中抽取出实体间潜在的关系事实。这些抽取出的宝贵的关系知识被广泛地应用于知识库构建与补全、互联网检索、对话系统等多种下游任务当中。然而,传统的关系抽取通常面向预定义的关系模式。这阻碍了相关技术在未知关系不断出现的真实场景下的应用。为了与真实的关系抽取场景相适配,许多研究者开始尝试从海量异构的文本中抽取开放类别的关系。
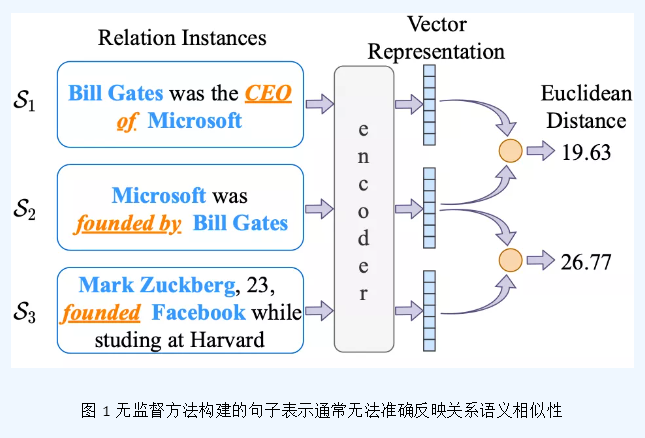
近年来,基于聚类的无监督关系发现逐渐受到许多研究者的关注。为了实现将表达相同关系的句子聚类的目的,构建合理的关系表示是这类方法研究的核心。现存方法大多使用人工定义的语言学特征或预训练模型中的知识构建或进一步优化关系表示。考虑到关系语义的复杂性,这种简单的无监督表示构建方法通常不能够精准地捕捉关系间的语义相似性。如图 1所示,尽管句子 和 表达不同的关系,其表示相似性依然高于表达相同关系的句子 和 。这可能是由于句子 和 之间更多的词重叠或句法相似性产生的结果。因此,其导出的聚类结果不能准确地对齐到关系语义类别上。
为了解决上述问题,本文提出了一种面向关系的聚类方法(A Relation-Oriented Clustering Method,RoCORE)以识别无标注数据中潜在的未知关系。为了使得模型学会聚类关系数据的能力,我们探索利用廉价易得的预定义关系的标注数据学习一种面向关系的表示。我们将表达相同关系的实例在表示空间中聚拢到其对应的关系质心周围形成一种簇状结构,因而学到一种聚类友好的表示。为了降低对于预定义关系的聚类偏置,我们通过一个联合目标函数同时在预定义关系的标注数据及未知关系的无标注数据上优化模型。实验证明,与现有SOTA的开放域关系抽取模型相比,RoCORE在两个主流的关系抽取数据集上分别降低了29.2%和15.7%的错误率。 相关研究成果A Relation-Oriented Clustering Method for Open Relation Extraction 发表于2021年的EMNLP会议上。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢