
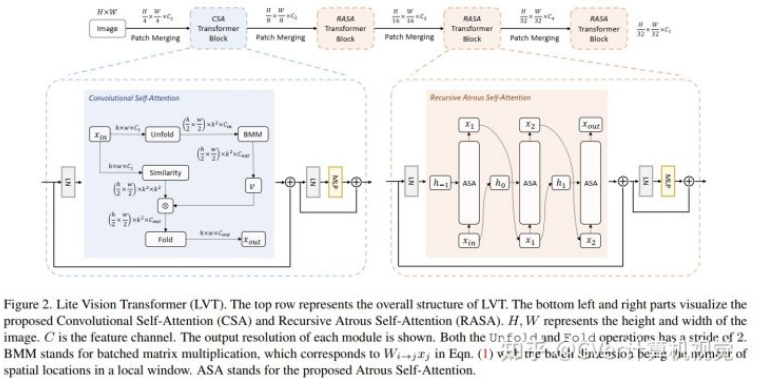
本文提出一种新型的轻量级Transformer网络,具有两个增强的自注意力机制,以提高移动部署的模型性能,在分类/检测/分割任务上综合表现优秀!代码将开源!

单位:JHU, Adobe
代码:https://github.com/Chenglin-Yang/LVT
论文:https://arxiv.org/abs/2112.10809
尽管视觉Transformer模型具有令人印象深刻的表示能力,但当前的轻量级视觉Transformer模型在局部区域仍然存在不一致和不正确的密集预测。我们怀疑他们的自注意力机制在"更浅和更薄"的网络中受到限制。
我们提出了 Lite Vision Transformer (LVT),这是一种新型的轻量级Transformer网络,具有两个增强的自注意力机制,以提高移动部署的模型性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢