
(作者:季紫荆 申雨鑫 孙毅宁 雨田 王鑫)
OpenKG地址:http://openkg.cn/dataset/c-clue
C-CLUE地址:https://github.com/jizijing/C-CLUE
众包标注系统地址:http://152.136.45.252:60002/pages/login.html
中国古籍博大精深、浩如烟海,凝聚着前人的心血和智慧,传承着华夏的精神和文明。史书典籍不仅是文化的延续,更蕴含着丰富的信息,如果能将不易理解的古籍文本形象展示给大众,对典籍进行通俗化、生动化的“转码”,把古籍变成读者可感知的作品,将有助于古籍焕发新生,从封闭走向世界。
在众多知识表示方式中,知识图谱(Knowledge Graph,KG)作为一种语义网络,拥有极强的表达能力,可以灵活地对现实世界中的实体、概念、属性以及它们之间的关系进行建模。相比于其他结构知识库,知识图谱的构建以及使用都更加接近人类的认知学习行为,因此对于人类阅读更加友好。知识图谱构建旨在组织并可视化知识,其基础是命名实体识别(Named Entity Recognition,NER)和关系提取(Relation Extraction,RE)这两项自然语言处理任务。
由于古代汉语与现代汉语在语法和词义上的巨大差别,手工标注其中的实体和关系耗时耗力。目前的主流技术预训练语言模型(Pre-Trained Language Model)能够在自然语言理解任务上实现较好的性能,然而,现有的中文理解测评基准及数据集大多为现代汉语,无法针对性地微调模型使之适应于古代汉语任务的特点。据我们所知,古代汉语领域仅有的NER任务数据集来自“CCL2020‘古联杯’古籍命名实体识别评测大赛”,其标注数据仅包含“书名”及“其他”两类实体,且规模有限。

图1 C-CLUE的构建框架图
如图1所示,我们基于结合群体智慧和领域知识的众包标注系统获取大规模、高质量的实体及关系数据,生成文言文语言理解测评基准及数据集C-CLUE,并使用该测评基准及数据集微调预训练语言模型。
(一)众包标注系统设计
我们设计并构建了一个众包标注系统,该系统引入“二十四史”的全部文本(约4000万字),并允许用户标注实体和关系。与现有的众包系统不同,在理解和标注文言文语料时,我们在系统中注入领域知识,并通过引入专业度得到高精度标注。具体而言,该系统通过在线测试判断用户的专业度,并在结果整合和奖励分配阶段考虑用户的专业度。另外,不同于注重任务分配策略的众包系统,本系统向每个用户开放相同任务,即“二十四史”的内容,并允许用户选择感兴趣的章节,对同一文本进行不同的标注,以最大限度地发挥群体智慧。
- 专业度评测方法(Professional Evaluation Standard)
(1)对于已知的专业度较高的用户,在将用户信息录入数据库时,直接将其角色定义为“专家标注用户”。
(2)对于未知用户,系统准备了具有标准答案的测试题目,并要求用户在第一次登录时进行作答。专业度将根据用户答题的准确率和题目的难度综合计算:(1) 根据志愿者的答题情况定义每道题目的难度初始值,难度值随着答题用户数的增加而动态变化,表示为答错的用户数量与参与答题用户总数的比值(取值范围为[0,1]);(2) 题目分数与难度成正比,定义为难度乘10后进行向上取整(例如,难度值为0.24,题目分数为2.4向上取整,结果为3);(3) 将所有题目分数之和作为总分,如果用户的得分高于总分的60%,将其角色定义为专家标注用户,反之,则将定义为普通标注用户。

图2 众包标注系统中的用户专业度测试页面
- 答案整合机制(Answer Integration Mechanism)
对于需要领域知识的文言语料标注任务,专业度高的用户更有可能做出正确的标注。例如,历史系学生比其他系学生掌握更多专业知识,做出正确标注的概率更大。因此,不同于现有的多数投票策略或引入准确度的方法,为了确保结果的准确性,本系统充分考虑了用户的专业度。
该众包系统允许用户修改界面上的现有注释,并将用户id、标注时间以及标注内容等信息录入数据库。如果多个用户对同一个实体或实体对有不同的标注,将分别保存它们而不是覆盖之前的标注。在下载数据时,如果有多条记录对应同一文本,则进行考虑用户专业度的答案整合,具体来说,系统为专家标注用户赋予的权重是普通标注用户的两倍,并采用加权多数投票策略来获得最终结果。
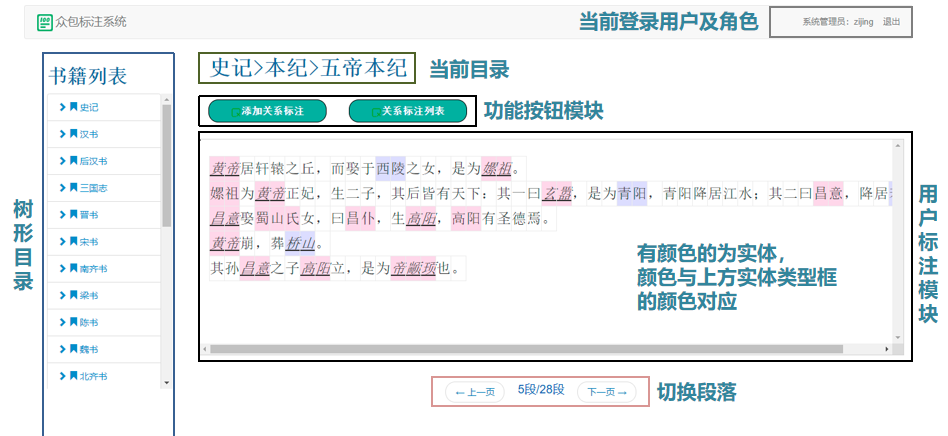
图3 众包标注系统中的用户标注页面
- 奖励分配策略(Crowdsourcing Reward Mechanism)
我们在现有众包系统的基础上,综合考虑专业度、标注准确率和标注数量,提出了一种新的奖励机制,并每隔固定时间结算一次奖励。
将答案整合后的最终结果视为正确结果,如果用户的标注与正确结果相同,则给予其奖励。对于专家标注用户,给予其双倍于普通标注用户的奖励。为了激励用户积极进行标注,该系统对标注的数量和正确率设置了阈值,并对超过该阈值的用户给予多倍奖励。
将一次标注的单价设为\( p \),标注数量阈值设为\( a_{t} \),标注准确率阈值设为\( c_{t} \)。如果一名普通标注用户在某一奖励分配周期内完成了\( n \)个标注,其中有效标注(与最终结果相同)为\( m \)个,且\( n \) > \( a_t \),\( m/n \) > \( c_{t} \),则该用户能够获得的奖励定义如下:
\( reward=m*(1+\frac{m}{n}-c_{t})*\frac{n}{a_{t}}*p \)
\( \)
(二)文言文语言理解测评基准及数据集C-CLUE构造
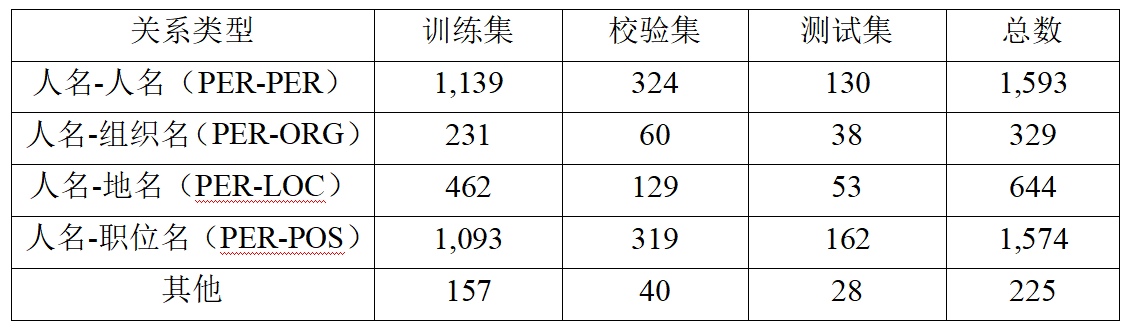
基于众包标注系统的实体和关系标注结果,我们构建了一个由NER和RE任务及其相应数据集组成的文言文语言理解基准。细粒度NER任务数据集由文本文件和标签文件组成,包括六类实体:人名、地名、组织名、职位名、书名和战争名。RE任务数据集包括七类关系:组织名-组织名、地名-组织名、人名-人名、人名-地名、人名-组织名、人名-职位名和地名-地名。
基于原始数据集,我们可以生成一个由句子和关系文件组成的关系分类数据集,以及一个类似于NER任务数据集的序列标记数据集。这时,生成的标签不再是实体类别标签,而是标志其为某关系的主体或客体的标签。
表1 用于命名实体任务数据集的统计数据

表2 用于关系抽取任务数据集的统计数据
(三)预训练语言模型微调
我们采用C-CLUE文言文语言理解测评基准及数据集微调预训练语言模型,如果模型能够在测试集上取得较好的准确率,可以考虑使用模型自动抽取未标注文本中的实体和关系,以进一步扩展数据集;如果准确率较低,则迭代从系统中获取新标注的实体和关系再对模型进行微调,直到模型能够在文言文任务上取得出色表现。
我们在基准测试中评估了以下预训练模型:BERT-Base、BERT-wwm、RoBERTa-zh和Zhongkeyuan-BERT(在下文中缩写为ZKY-BERT)。基线模型的介绍可参考GitHub项目。
表3 在六类实体数据集上的实验结果(%)
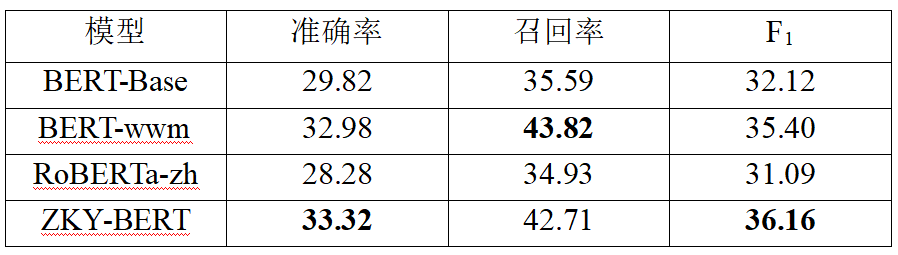
表4 在四类实体数据集(去除了人名、地名、组织名、职位名外的其他实体)上的实验结果(%)
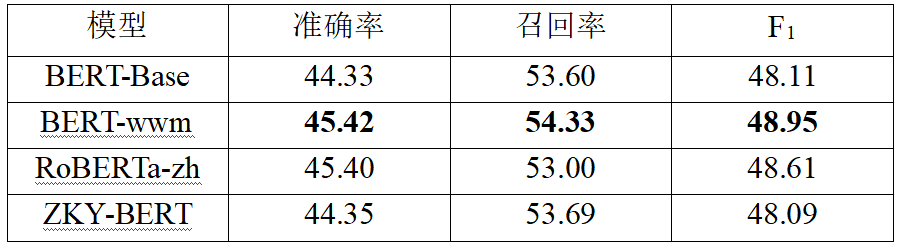
从表3的结果可以看出,在处理细粒度NER时,在文言语料库上训练的ZKY-BERT模型表现最好,适应中文特点的BERT-wwm模型次之。从表4的结果可以看出,由于实体类型的减少,预训练模型都取得了相对较好的性能。
对于RE任务,我们将其拆分为两个子任务:关系分类和序列标记。实验表明,基线模型在关系分类任务上可以达到47.61%的准确率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢