
本文分享论文『Multi-Modality Cross Attention Network for Image and Sentence Matching』,由中科大&快手联合提出多模态交叉注意力,《MMCA》,促进图像-文本多模态匹配!

论文链接:
图像和句子匹配的关键是准确测量图像和句子之间的视觉语义相似性。但是,大多数现有方法仅利用每个模态的模态内关系或图像区域与句子词之间的模态间关系来进行跨模态匹配任务。
与他们不同的是,在这项工作中,作者通过在统一的深度模型中联合建模图像区域和句子单词的模态内和模态间关系,提出了一种新的图像和句子匹配的多模态交叉注意 (MMCA) 网络 。
在提出的MMCA中,作者设计了一种交叉注意机制,该机制不仅能够利用每个模态的模态内关系,而且能够利用图像区域与句子单词之间的模态间关系,以相互补充和增强图像和句子的匹配。在包括Flickr30K和ms-coco在内的两个标准基准上进行的广泛实验结果表明,所提出的模型在图像-句子匹配模型中达到了SOTA的性能。
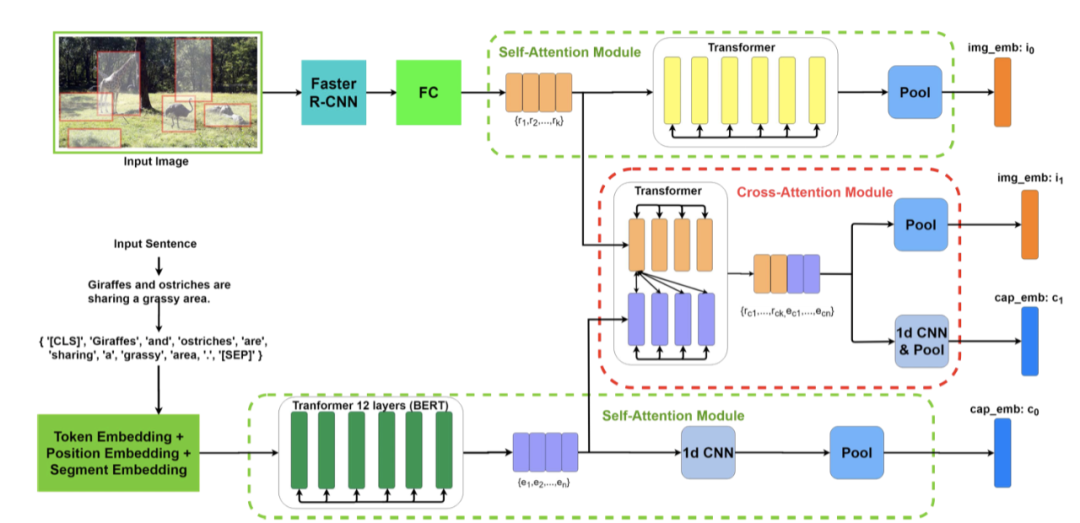
如上图所示,本文的多模态交叉注意网络主要由两个模块组成,即自注意模块 和交叉注意模块,分别在图中的绿色虚线块和红色虚线块中进行了展示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢