
大家好,今天为大家带来一篇KDD2021年的文章:《An Embedding Learning Framework for Numerical Features in CTR Prediction》。该文章介绍了一种对连续特征进行embedding的方法:AutoDis。该方法具有以下三种优点:1. 高模型容量。2. 端到端训练。3. 连续特征embedding具有唯一的表示。
动机与介绍
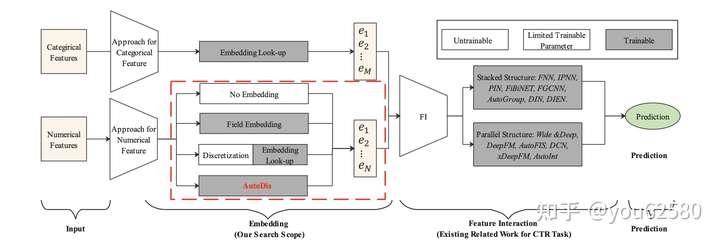
如图1所示,目前大多数的CTR预估方法遵循Embedding&Feature Interaction架构。由于CTR预估任务中特征交叉(Feature Interaction)的重要性,目前大多数的工作围绕着研究特征交叉的方法。然而Embedding的方式也同样重要。有以下两点原因:
- Embedding模块是特征交叉的基础。
- Embedding模块的参数量最多,对预测结果有着深远的影响。
如图1.所示,对于类别型特征(Categirical Features),由于类别型特征取值有限,一般采用查表(look-up)的方式来进行embedding。然而对于连续(数值)型特征,由于其无限的取值,缺少一种十分有效的embedding方法。如图1所示:目前的连续型特征embedding方法主要为以下三种:
- No embedding: 直接使用其原始值输入DNN来进行embedding。
- Field Embedding:为每个连续特征域单独学习一个embedding向量,然后用原始值与embedding向量相乘。
- 离散化:将连续(数值)型特征进行离散化分桶,然后采用类别型特征的embedding方法(查表(look-up))。
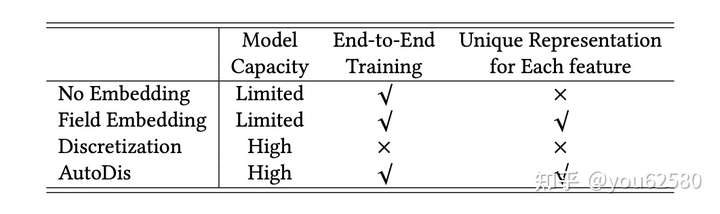
然而,前两种方法的表示容量较低(low capacity of representations),可能会导致次优结果。最后一种方法会存在SBD (Similar value But Dis-similar embedding) 和 DBS (Dis-similar value But Same embedding)问题。
为了解决上述问题,该文章提出了AutoDis方法。在AutoDis方法中,首先为每个连续特征域设计一个 meta-embeddings来学习全局共享的知识;接着,我们设计了可导自动离散化过程,捕捉连续型特征与meta-embeddings的关系,最后我们采用一种聚合方法来为每个特征学习一种连续但不同且唯一的embedding。我们将在下文详细介绍。
预备知识
我们首先介绍连续型特征常用的三种embedding方法:
1. No embedding
这种方法直接采用连续型特征的原始值进行变化而不是学习其embedding。例如Wide&Deep 架构。在DLRM架构中,使用多层感知机结构来对所有数值型特征进行建模:
No embedding方法由于其低容量模型的结构,很难捕捉到数值特征领域的知识特征。
2. Field Embedding
在学术界中最常用的方法是Field Embedding,所有的在一个领域(field)的数值型特征都共享一个embedding,然后乘以他们的特征值,表达如下:
其中为第
个连续特征领域的embedding,
。然而这种方法由于表示容量有限以及不同特征领域内的linear scaling relationship,限制了这种方法的表现。
3. 离散化
工业界对连续特征的embedding方法一般为离散化,首先将连续型特征进行离散化,分成类别,然后采用查表的方式进行embedding。表达方式如下所示:
其中为第
个连续特征领域的embedding矩阵,
为连续特征离散化后的种类个数。
为手动设计的分类策略,该策略将特征
分到
个类别中。如图2所示,这种方法会遇到以下三种问题:
- TPP (Two-Phase Problem):该方法不能端到端优化,例如不能自动优化分类策略
。
- SBD (Similar value But Dis-similar embedding): 相似的特征值可能有完全不同的embedding。
- DBS (Dis-similar value But Same embedding): 完全不同的特征值可能会有相同的embedding。

AutoDis 方法介绍
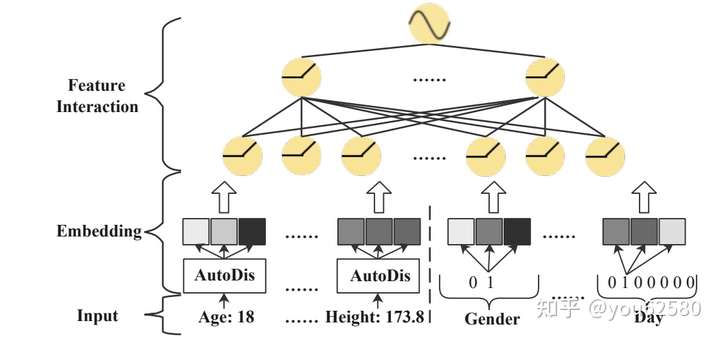
为了解决上述问题,文章提出了AutoDis,AutoDis由:Meta-Embeddings,Automatic Discretization,以及Aggregation Function组成。 AutoDis的大致流程如下:
- 首先,AutoDis为每一个领域(field)的连续型特征定义了一组Meta-Embeddings。
- 接着,AutoDis自动(可学习)对每个领域的特征值进行离散化,并将其分配到不同的Meta-Embeddings桶中(每个领域的特征值可能分到一个桶中也可能多个桶)。
- 最后采用一种聚合方法,将多个桶的embedding结果聚合,得到最后连续特征值的embedding。
AutoDis方法与其他三种embedding方法对比的优劣如图3所示: 我们接下来将详细介绍AutoDis方法的每个步骤。
Meta-Embeddings
AutoDis为每一个领域(field)的连续型特征定义了一组Meta-Embeddings:。其中
为meta-embeddings的个数。相比于为每一个领域(field)的连续型特征定义一个embedding的Field Embedding方法,AutoDis具有更高的模型容量。
自动离散化(Automatic Discretization)
首先,AutoDis采用一个两层神经网络,输入连续特征值,输出连续特征值分配到不同的Meta-Embeddings桶(个)中的logit:
其中,
。分配的最终结果
。最后我们将
通过softmax层,得到该特征值分配到每个桶的概率。例如,分配到第h个桶的概率如下:
其中,控制着分桶的离散分布程度。当
趋向于无穷,分布趋向于平均分布,当
趋向于0时,则趋向于one-hot分布。
可以手动定义,也可以将特征
的统计分布(CDF或者均值)通过两层神经网络学习得出。
聚合方法
在经过自动离散化后,我们得到了特征值分到不同Meta-Embeddings桶的概率,我们接下来将通过一些聚合方法得到最后的embedding:
- 最大池化:选取概率值最高的Meta-Embeddings桶作为特征值的最后embedding表示。
- Top-K 求和: 选取概率最高的top-k embedding求和。
- 加权平均:用概率逻辑值
加权平均得到。
经过上述流程后,我们得到了特征值连续不同且唯一embedding表示。
实验
实验主要在以下数据集进行展开:Criteo, AutoML 和 一个工业数据集。
文章的实验从以下几个方面来与其他方法进行比较:
1. 不同embedding方法比较:
基线模型采用DeepFM:
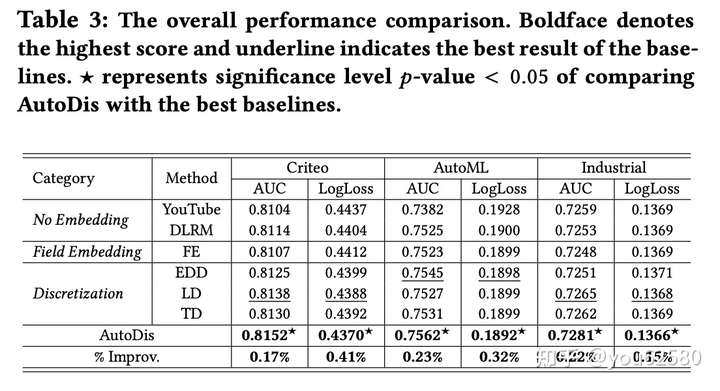
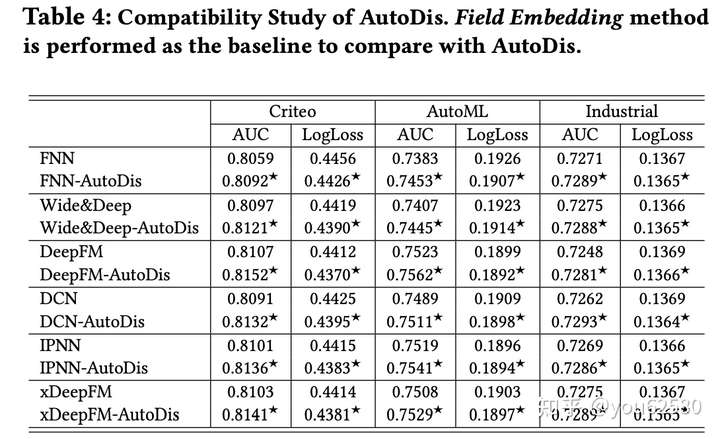
可以看到,AutoDis优于其他的embedding方法。且对大多数的CTR模型都有效。
2. Embedding可视化分析:
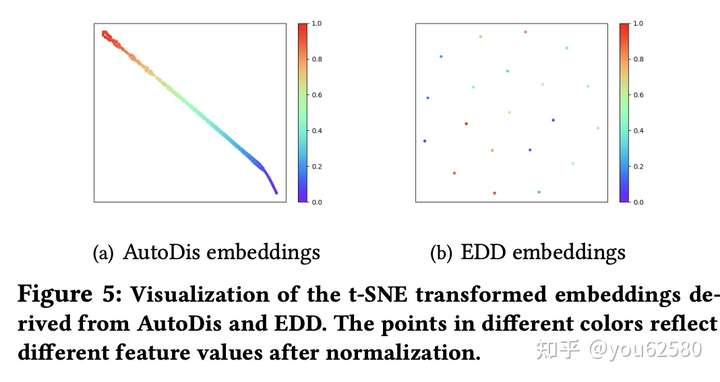
不同的值用不同颜色表示,可以看到AutoDis的embedding表示相对于分桶方法来说,更集中且平滑。
3.特征值分桶权重分析:
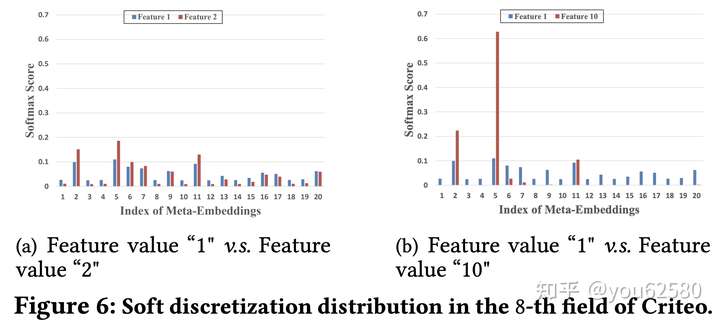
我们将特征值1,2 得到的分桶权重以及特征1,10的分桶权重可视化,可以看到,特征值1,2具有相似的分布,而1,10之间的差异较大。
4. 加入数值型特征对结果的影响:

通过在只有类别型特征的模型,逐渐加入连续型特征,模型的AUC会有着逐步提升。
5. 不同聚合方法的比较:
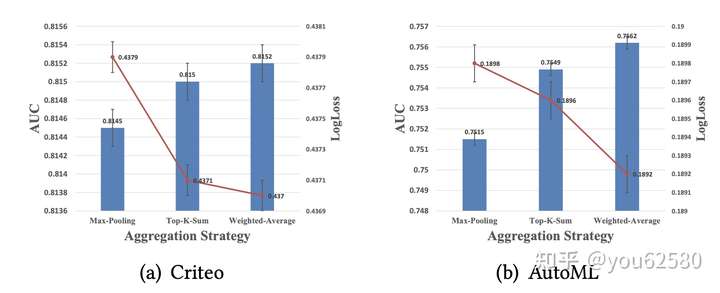
其中加权平均效果最好,这是因为加权平均用了更多的信息。
6. 不同的![[公式]](https://www.zhihu.com/equation?tex=%5Ctau) 对结果的影响:
对结果的影响:
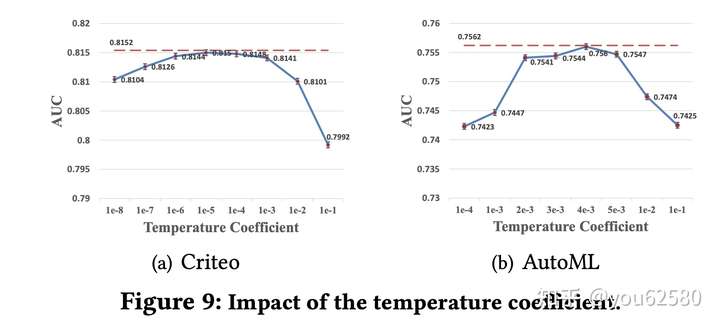
其中红色的虚线代表模型习得的,可以看到,我们的AutoDis可以自适应的习得最优的
。
7. 不同的meta-embedding数目对结果的影响:
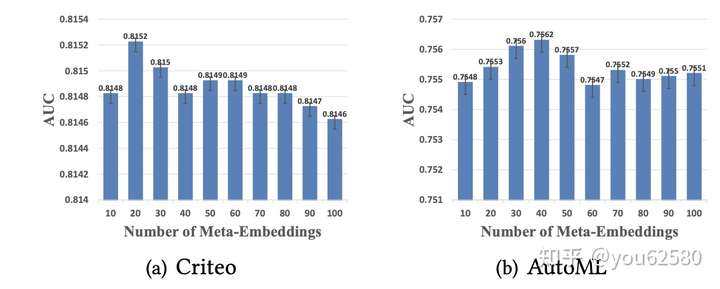
可以看到,桶的数目不是越多越好,会有一个最合适的分桶数目。
总结
该文章提出了AutoDis。该方法具有以下三种优点:1. 高模型容量。2. 自动离散化,端到端训练。3. 连续特征embedding具有唯一的表示。感兴趣的同学可以动手实践下,该文章已开源[1]。笔者认为,该文章具有很好的借鉴价值,大家可以在自己的任务上或者业务中进行尝试,欢迎大家交流。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢