
- Title: PANDA: Adapting Pretrained Features for Anomaly Detection and Segmentation
- Conference: CVPR 2021
- 论文代码: GitHub - talreiss/PANDA: PANDA: Adapting Pretrained Features for Anomaly Detection and Segmentation (CVPR 2021)
写在之前:预训练的模型以及特征表示已经广泛的在NLP任务以及CV任务中得到了应用,该种思想能否同样应用在异常检测任务中?如果可以的话,应该如何应用?这篇paper给予了很好的解答...
ps: 这模型缩写也有点意思昂——正好是大熊猫?(在这里也推荐给大家一个网站用来根据文本生成你的模型缩写名称:Automatically generate fun acronyms for your project)
一、讨论的问题
此次分享的这篇paper,其主要讨论的问题也正如标题所示:如何将预训练模型提取到的特征向量应用至异常检测任务中?论文主要在三个异常检测任务中讨论了这一问题:
任务1:图像异常检测——训练过程中如果只有带标签的正常样本,如何检测异常的图像?
任务2:图像异常分割——训练过程中如果只有带标签的正常样本,如何检测出所有异常像素(更加精细的检测任务)?
任务3:OOD(out-of-distribution)检测——当有训练数据分布外的样本出现,如何检测出该类异常?
二、主要发现
该篇paper在上述三个问题中,探究了如何将预训练模型以及预训练模型得到的特征向量更好的应用至异常检测任务中,通过实验,文章发现了如下几个比较有趣的结论:
1. 利用一个预训练的模型(例如在ImageNet上预训练的ResNet),不微调,直接将这个模型作为特征提取器,然后结合简单的KNN算法判断样本的正常/异常类别,就能超过许多SOTA的模型。该种做法在任务1、2中都可行。
任务1中,作者提出的模型为DN2(Deep Nearest Neighbours),表示利用预训练模型(不微调)得到的特征向量通过KNN算法进行类别预测;
任务2中,作者提出的模型为SPADE(Semantic Pyramid Anomaly Detection)只是把这个思路用在了pixel级别的图片中,并且把预训练模型中多个神经层的feature进行了拼接(目的在于得到low-level的feature以及high-level的feature),之后用KNN distance来判断某个像素的正常/异常类别。
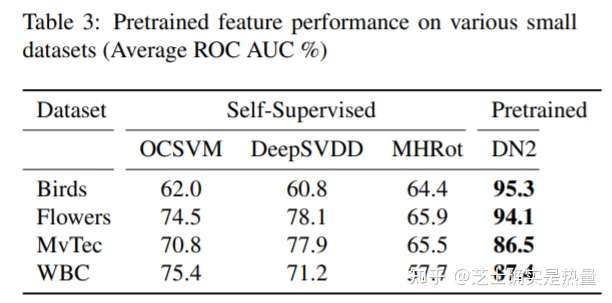
直接放出实验结果,在任务1中(Table2、3)可以看到——简单的采用预训练feature(不微调)+KNN的做法,已经可以达到非常好的性能!DN2模型在一系列CV异常检测数据集中表现已经好于目前一些SOTA模型,例如OC-SVM、DeepSVDD以及MHRot;此外,该方法在像素级别的异常检测任务中(Table4)同样有效,SPADE模型也取得了非常好的效果。

2. 尽管上述做法的效果已经不错,但实际上预训练的模型可以在异常检测下游任务中进一步微调(仅用预训练模型不微调+KNN当然不能发CVPR)。由于异常检测任务本身的特殊性,直接用有监督方式进行微调是行不通的。而作者指出,其提出的微调方法PANDA,即便相较于目前比较流行的异常检测下游微调任务——OCC(one-class classification)而言,性能也具有显著的优势。
三、现有工作的做法
本篇博文从此处开始主要介绍文章的核心模型——PANDA。如果想进一步探究PANDA模型,我们需要先知道以往的学术文章是怎么在异常检测任务中对预训练模型进行微调的。概括的说,包括PANDA在内的学术文章都在做一个事情:得到预训练的feature extractor( )——微调feature extractor(
),再利用微调的feature extractor训练异常检测模型。而微调feature extractor到训练异常检测模型往往采取的是end-to-end方式,而不是two-stage分离式的训练过程。

- DeepSVDD
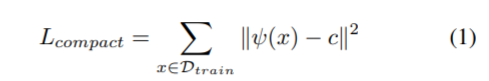
DeepSVDD(ICML 2018)是one-class classification中较为经典的一种方法。DeepSVDD首先利用deep autoencoder在所有样本中进行预训练(PANDA文中写的是在正常样本中进行预训练,但实际Deep SVDD是unsupervised method,自然也没有哪些是正常样本的信息)得到 ,然后将所有训练样本经过
得到的表示向量的均值作为中心点
。在微调阶段,DeepSVDD利用上述的loss function使得样本的表示尽可能接近于中心点
,进而以样本特征向量与中心点之间的距离作为样本异常程度的衡量。
问题:DeepSVDD中神经网络的偏置项(bias)是需要设置成0的,否则网络可以简单的将所有的weight学习成0,bias学习为 ,从而将所有样本点均映射到同一个特征向量
。这样虽然会使得loss function值为0,但显然是没有意义的(也即常说的mode collapse)。
- Joint Optimization(JO)
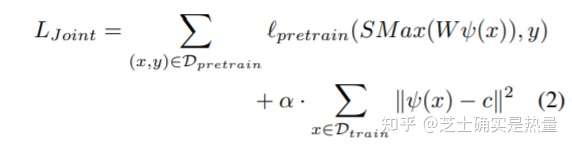
思路:在理解了Deep SVDD的思想后,JO的思想是好理解的。JO在Deep SVDD compactness loss基础上增加了一项预训练分类任务中的交叉熵loss。即微调过程中,JO强制模型既要将特征向量尽可能压缩到中心点 ,还要使得特征向量保证原来的分类作用(用原文的话来说是“due to the fear of learning a trivial solution in the absence of penalty for miss-classification”)。
问题:JO方法需要在微调阶段保留预训练的数据集(例如在此处需要保留预训练的数据集ImageNet),因此需要额外占一部分的内存,效率并不高;此外,这种Multi-task的训练思路,可能会导致第二部分loss( )没有训练到最优,而这部分训练目标对于下游异常检测任务而言是至关重要的。
四、PANDA核心思想
PANDA模型的核心仍旧是通过DeepSVDD中的compactness loss来将特征向量尽可能压缩至中心点 。但PANDA并没有用DeepSVDD中将偏置项设为0,或者是JO中额外引入预训练损失函数的做法。PANDA通过以下的三种策略来防止mode collapse:
- simple early stopping (PANDA-Early)
最简单的方法,就是在mode collapse之前将模型early stopping,但由于paper异常检测问题场景的设定(在训练阶段只有正常样本),使得无法通过常规的验证集+early stopping的方法有效解决这一问题。不过就如文章中所表述的,也可以将early stopping的epoch看做一个超参进行设置。
- sample-wise early stopping (PANDA-SES)
作者进而采用了一种sample-wise的早停机制,即每个样本的early stopping epoch不同。如何做到根据每个样本自动选择最优的early stopping epoch呢?可以参考文中Figure 3的这张图(作者应该也是通过实验现象反推出来这样做是有效的):
右图:如果将每个样本点到中心点 的距离通过所有样本的平均距离进行标准化,正常样本到中心点
的距离往往不会受到影响(因为正常样本占了样本的绝大多数),异常样本到中心点
的距离先上升后下降,而拐点往往也是mode collapse的标志,也进而影响最终的AUC。
明白了这个原理之后,simple-wise early stopping就变得好操作了——例如右图中epoch=50,每隔5个epoch保存模型的参数(共10个),以及该参数下所有样本离中心点 的平均距离。在测试阶段,将当前测试样本与中心点
的距离在这10个保存的模型中全部计算一遍,并通过训练阶段得到的平均距离进行标准化。拿出最高的距离(分数)作为最后的异常得分,这样如果当前样本为正常样本,得分基本是稳定的(右图中0~50个epoch正常样本得分基本都接近),如果当前样本为异常样本,往往能选择到最优的(mode collapse之前)的情况(例如epoch=20)。
- continual learning(PANDA-EWC)
读者们听到这里可能又犯困了,怎么又出来个continual learning术语?别急,我们来看一下这个“华丽”的术语下的本质是什么:
continual learning目的在于不让网络在学习过程中遗忘之前学到的知识——简单的方法是将网络权重的改变也视为一个正则项加到loss function中,这样往往是缓解网络遗忘问题的一个有效方法——神经网络中不同权重的重要性是不同的,对于feature提取的重要性也是不同的,这种强制对所有的权重统一正则化的方法存在问题——利用Fisher information matrix改善该问题:
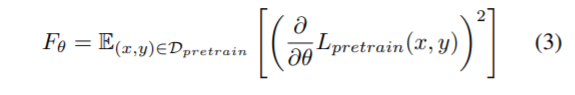
注意到Fisher information matrix实际上矩阵的元素值为对应参数的梯度,即赋予更大的权重给梯度大的参数。
最后,在原来的compactness loss后面加上利用fisher information matrix改良的参数变化正则项。
五、实验结果
说了这么多,让我们来看看最后PANDA模型的实验效果吧!
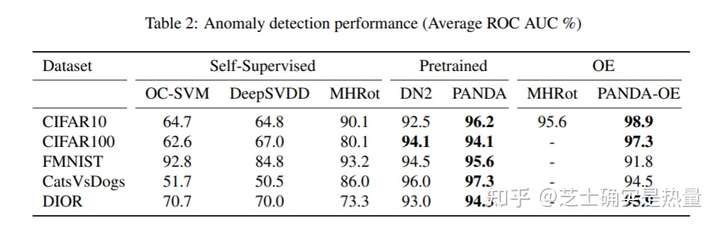
如上表所示,PANDA模型(此处展示的是PANDA-EWC模型)相较于其余SOTA模型而言,以及直接用预训练模型特征+KNN的DN2模型而言,优势是明显的。并且这一优势在任务3的OOD检测中也成立(此处对应表中OE列)。
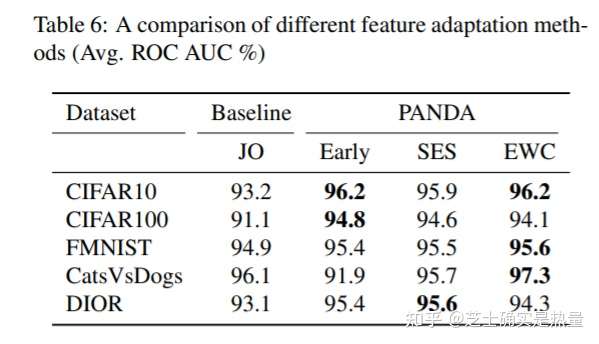
此外,作者也探究了PANDA的三种变体:PANDA-Early,PANDA-SES以及PANDA-EWC的对比效果。实验发现这三种方法都优于Joint Optimization (JO)方法,且PANDA-EWC整体而言更优。此外,作者还发现如果将fisher information matrix设为等权,EWC方法将会退化为early stopping方法。
文章中还对self-supervised feature与pretrained feature、以及pretrained feature的迁移性等问题展开了探究,此处就不一一展开了,感兴趣的读者可以查找原文进行阅读。
六、结论与启发
PANDA的整体思路还是清晰的,即预训练模型是否对于异常检测任务也是有帮助的?这个猜想通过直接用预训练模型得到的特征+KNN模型即可得到SOTA的表现得以验证。进而,文章提出了PANDA模型,通过三个合理的方法设计,对预训练模型如何在异常检测下游任务中进行微调做出了改进。
当然,文章也不是完美的(ps:文章曾被ICLR 2021 reject),个人感觉主要有以下几点:
- baseline不太够,文章提出的SOTA表现实际上也只跟了OC-SVM、DeepSVDD以及MHRot三个方法比了一下,而OC-SVM这种shallow model可能算不上是一个较强的baseline;
- 文章的主体还是在DeepSVDD上做一些改进,属于DeepSVDD模型的一个延伸,而不是从根本上的模型创新。DeepSVDD将样本点的映射空间强制压缩到一个中心点
的做法,可能并不是最优的;
- PANDA的三个变体,实际上是在ICLR2021被拒后作者添加的,有强行为了paper进行“缝合怪”的嫌疑。并且这三种变体更多的应该称之为“策略”,而不是创新性的改进,应用场景有限,可能只能针对特定的模型架构。
参考文献
PANDA——Reiss, Tal, et al. "PANDA: Adapting Pretrained Features for Anomaly Detection and Segmentation."Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
DeepSVDD——Ruff, Lukas, et al. "Deep one-class classification."International conference on machine learning. PMLR, 2018.
Joint Optimization——Perera, Pramuditha, and Vishal M. Patel. "Learning deep features for one-class classification."IEEE Transactions on Image Processing28.11 (2019): 5450-5463.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢