
先导知识
前言
计算机视觉(Computer Vision)和自然语言处理(Natural Language Process)是深度学习领域近年来最为火热的两个方向,而且两个方向的之间的鸿沟也越来越狭小。尤其是Transformer [2]提出之后,似乎有了两个方向都被Transformer统一的趋势。因此,视觉和语言学的多模态也成为了一个火热的研究方向,这里为大家带来的是一篇比较早期的多模态的论文:由FAIR提出的ViLBERT[1]。ViLBERT是一个多模态的预训练模型,首先它将文本和图像数据分别输入两个独立的流,如图1所示,它的上面的是图片流,下面的是文本流。接着使用他们提出的互注意力Transformer(Co-Attention Transformer,Co-TRM)层将两个特征进行融合,最后得出两种不同数据的各自的特征编码。这些特征可以被应用到不同的多模态的任务中,例如视觉问答,图像描述生成等。

1. 模型结构
如图1所示,ViLBERT是由两条并行的BERT组成,分别用于处理图像数据和文本数据。ViLBERT的每个流均是由Transformer和Co-TRM层组成,Co-TRM层的作用是用来将图像特征和文本特征进行信息交互。Co-TRM位于红色虚线框所示的位置,它和普通的Transformer共同构成一个基础的网络块,可以通过控制它们的个数 来调整模型的容量。注意在Co-TRM之前的文本流,它还多加了
个Transformer来对文本进行更深层次的编码。
1.1 输入数据
图像的特征是根据Faster R-CNN[4]计算而来,它先将Faster R-CNN在Visual Genome上进行预训练。然后将图像输入训练好的Faster R-CNN中,它会输出若干个ROI,接着我们根据ROI的分类置信度选择10到36个大于某阈值的区域。最后使用平均池化得到这些选择区域的特征向量,它们将共同作为该输入图像的典型特征向量输入到后面的Transformer中。为了反应ROI在图像中的位置和大小,作者在输入数据中加入了一个5维的特征向量,他们分别是ROI的左上角,右下角,以及ROI的面积相对于图像面积的比例。
而文本的嵌入向量则和BERT保持一致,即由Word2Vec,位置嵌入以及分割嵌入组成。
1.2 互注意力Transformer
ViLBERT最大的创新点是提出了互注意力Transformer(Co-TRM),它的网络结构如图2所示。它的输入是视觉流特征 和文本流特征
,它们首先经过权值矩阵得到各自的Q,K,V特征,如式(1)。在计算视觉特征的输出值
时,它使用的是来自自身的$Q_V$和来自文本的
,
。同理在计算文本特征的输出值
时,它使用的是来自自身的
和来自图像的
,
,如式(2)。Co-TRM的最大改进点在于将两个流的Key和Value进行了互换,从而实现了两个不同流的信息融合,而剩下的内容就和Transformer完全一样了,包括全连接和残差结构。
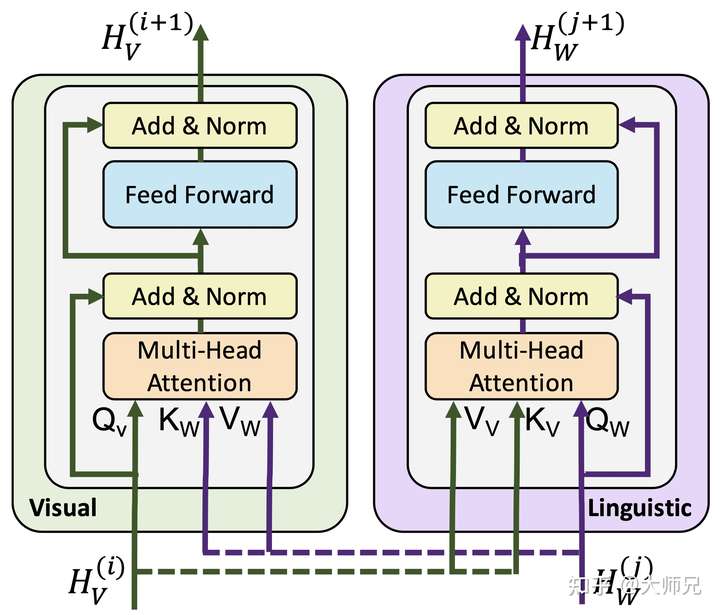
那么为什么Co-TRM会互相交换K和V呢,我们可以从信息检测的角度去理解。在Self-Attention中,Q扮演的是查询(Query)的角色,它通过点乘计算与每个键(Key)的相似性,然后将他们为每个特征值(Value)计算一个权值。在Co-TRM中,我们根据流A的查询和流B的键为流B的每个特征的权值,以此作为流A的输出特征。它的物理意义流A根据自身来从流B中选择一部分特征,这一部分特征是更适合融合到流A中的。
从实验结果来看,在控制相同预训练参数的情况下,双流注意力机制是比单流注意力机制效果要好的。
2. 预训练目标
ViLBERT有两个预训练目标,他们分别是掩码多模态模型(Masked Multi-Model Modelling)和多模态对齐预测(Multi-Model Alignment Prediction)。它的两个任务均是通过Conceptual Captions数据集[5]构建的。Conceptual Captions数据集有300万张图像和它的描述,其中描述文本是根据HTML的Alt-Text属性获得的。
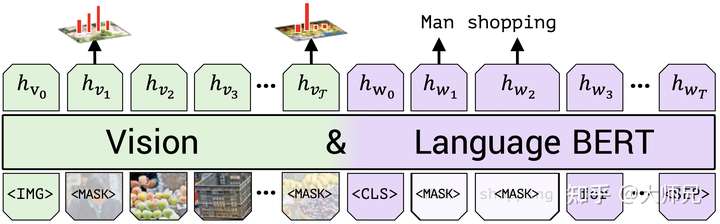
2.1 掩码多模态模型
掩码多模态模型参考的BERT的掩码语言模型(MLM)。对于文本流,掩码多模态模型保持了MLM相同的策略,即使用15%的掩码比例中80%被替换成[MASK],10%被随机替换,10%保持不变。
但是对于图像流,ViLBERT的输入是ROI的Feature Map的特征编码,直接还原这个值的话对于模型来说难度太大,很难收敛。因为Feature Map上的特征本质上式一个分布,它精确的值并不重要,所以ViLBERT这里将两个分布之间的KL散度作为了优化目标。即图像流的目标是最小化模型预测的被掩码的图像区域的特征和原始特征的KL散度。
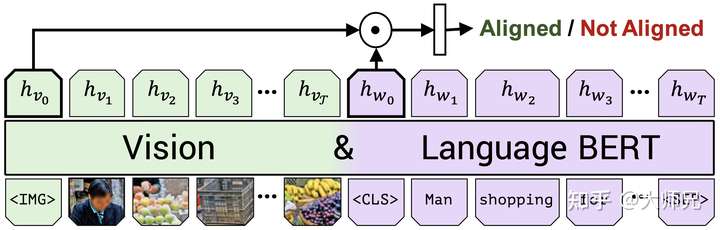
2.2 多模态对齐预测
多模态对齐预测任务是预测输入模型的文本和图像是否是匹配的,流程如图4。它的输入是没有掩码的图像流和文本流,输出是两个流编码的特征向量。然后通过点乘将两个特征向量合成一个向量,最后输出层是一个二分类模型,用来判断输入的图像和文本对是否是对齐的。
3. 模型微调
ViLBERT共有4个微调任务,它们依次是视觉问答(VQA),视觉常识推理(VCR),图像区域定位和基于描述的图像检索。
3.1 视觉问答
视觉问答(Visual Question Answering,VQA)任务取自数据集VQA 2.0[6],它 包含110个基于COCO数据集中图像的问题,每个问题有10个答案。在这个任务中,我们将图像和问题分别编码成 和
,然后通过点乘将它们合并成一个特征向量。在这里,VQA任务被视作一个多标签的分类任务,即对候选答案中的每个答案的得分进行预测,所以最后接了一个双层的MLP得到3192个可能的答案。对于每个候选答案,根据它们与标签答案的相似性计算一个软目标得分(soft target score),这个软目标得分将作为回归的目标。
3.2 视觉常识推理
视觉常识推理(Visual Commonsense Reasoning,VCR)的任务的数据集取自VCR数据集,包括来自11万个电影场景的29万个QA问题。包括视觉问答(Visual Question Answering,Q→A)和答案证明(Answer Justification,QA→R),这两类问题都可以统一为多分类问题。具体的实现是将问题和答案连接起来,形成四组不同的文本输入。然后将文本和图像一起输入ViLBERT,最后再加一个分类层,为每组图文对打分。
3.3 图像区域定位
图像区域定位(Grounding Referring Expressions)的目标是根据文字在图像中标注出对应的物品,数据集取自RefCOCO+数据集[7]。在VilBERT中,它先通过Mask R-CNN识别出ROI区域,然后计算各个区域和文字匹配的得分,将最高区域作为最终的预测结果。
3.4 基于描述的图像检索
基于描述的图像检索(Caption-Based Image Retrieval)是根据文字描述在图片池中搜索图片。任务取自Flickr30k数据集[8],共有31000张图片,每张图片有5个标题。检索任务被构建成四选一的问题,对一个每个任务,我们随机选择一个标题和图像对,以及随机抽取的三个干扰项(一个随机图片,一个随机文本和一个难分样本)。然后计算每一项的对齐分数,然后使用softmax得到最终的预测结果。
3.5 零样本的基于描述的图像检索
在这里,我们直接将预训练的多模态对齐预测机制应用到Flickr30k数据集,而不进行微调。这个任务旨在验证多模态预训练模型是否学到了有实际语义意义的特征。
总结
ViLBERT将BERT扩展到了视觉和语言的多模态的版本。该模型包括两个并行的信息流,其中文本流和图像流的底层仍是BERT。ViLBERT在结构上的最大创新点是引入了互注意力Transformer来使两个流的特征进行交互。
在提取文本特征时,ViLBERT使用的是基于Faster R-CNN提取的ROI,因此可以看出ViLBERT并不是一个端到端的模型,在之后的视觉Transformer中,基于Patch的方法更多的被采用。因为图像流的输入是特征分布,因此ViLBERT使用了KL散度作为损失函数,而不是对特征进行重建,这也是提升模型效果的一个重要的点。
Reference
[1] Lu, Jiasen, et al. "Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks." arXiv preprint arXiv:1908.02265 (2019).
[2] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[3] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[4] Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems 28 (2015): 91-99.
[5] Sharma, Piyush, et al. "Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning." Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018.
[6] Antol, Stanislaw, et al. "Vqa: Visual question answering." Proceedings of the IEEE international conference on computer vision. 2015.
[7] Kazemzadeh, Sahar, et al. "Referitgame: Referring to objects in photographs of natural scenes." Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 2014.
[8] Young, Peter, et al. "From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions." Transactions of the Association for Computational Linguistics 2 (2014): 67-78.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢