
年底了,想看看各大咨询公司或者科技公司的发布的AI领域榜单,结果搜了一圈,发现还没人做这个系列的专题,故打算自己做一个「野鸡」榜单。
在小群里讨论了下,选出了今年AI界的一些成果。本来还给这些成果打分的,但考虑到我们不是什么权威机构,纯粹是几个技术爱好者讨论,打分容易引起争议,所以就放弃打分排序了,直接按成果发表/公布的时间排序。
本文的目的,不是为了比较哪个AI成果更牛,而是尽量让更多人了解到今年AI行业的进展,以及发展趋势。如榜单未必如大家所想的一样,或者漏了某个很强的技术,也欢迎大家补充你认为更厉害的AI成果,在评论区补充(当然,最近知乎评论区不能用,你可以用赞同+推荐的方式告诉我,好的东西我一定会补充进来)

年度10大AI成果(按时间排序)
1. Switch Transformers
发表时间:2021年1月11日
论文地址:Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
亮点:
- 以将语言模型的参数量扩展至 1.6 万亿。
- 由于采用了混合专家(Mix of Expert,MoE)对于不同的输入,会选择不同的参数。多个专家(或者专门从事不同任务的模型)被保留在一个更大的模型中,针对任何给定的数据,由一个“门控网络”来选择咨询哪些专家。结果即使参数爆炸,但计算成本不变。
知乎相关讨论:


2. SEER(SElf-supERvised)
发表时间:2021年3月2号
论文地址:Self-supervised Pretraining of Visual Features in the Wild
亮点:
- 自监督,10亿个参数,在几乎没有标签帮助的情况下识别图像中的物体
博客:

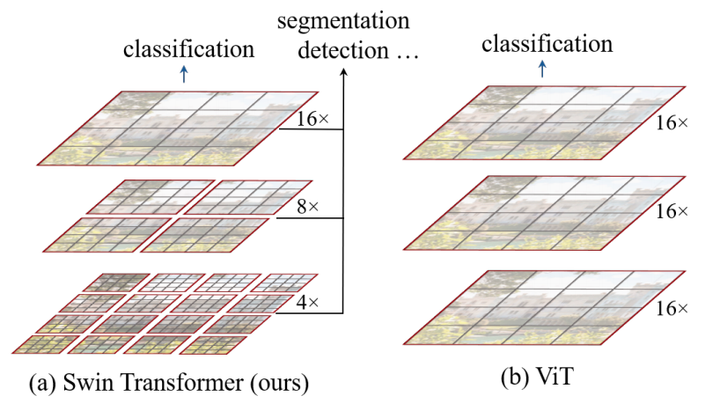
3. Swin Transformer
发表时间:2021年3月25号
论文地址:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
亮点:
- ICCV2021的 best paper
- 证明transformer模型在CV任务上表现能超过CNN
- 促进CV和NLP架构的融合
文章的几位作者现身知乎作答:
4. SSViT
发表时间:2021年4月29号
论文地址:Emerging Properties in Self-Supervised Vision Transformers
亮点:
- 和SEER类似,也是无标签自监督的,不一样的是,此文章关注的是自监督用在vision transformer上。
- 文章有证据表明自监督学习可能是开发基于 ViT 的类 BERT 模型的关键。

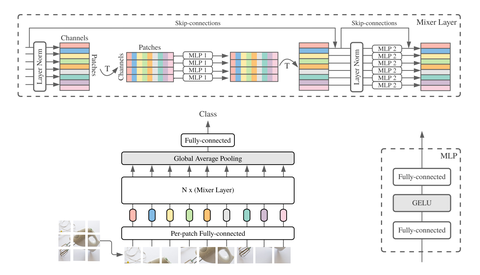
5. MLP-Mixer
发布时间:2021年5月4号
论文地址:MLP-Mixer: An all-MLP Architecture for Vision
亮点:
- 虽然没有SOTA,但性能不错
- 卷积、循环,注意力什么的,都没用上。
不过Yann LeCun说,这种技巧只是「烹饪艺术」

知乎相关讨论:
6. GitHub Copilot
发布时间: 2021年6月19号
项目地址:GitHub Copilot.
在把Github Copilot选进来是,我是有点犹豫的,因为Github Copilot确实有很多争议,例如违反开源协议,代码抄袭等等。但从技术角度来看,这确实是一个不错的玩法,而且自动补全的代码很强,甚至还能刷LeetCode,我也用过一段时间,确实能帮助我提高写代码效率。当然,不要依赖它,毕竟它写的代码不能保证是没bug的。
相关视频讲解:
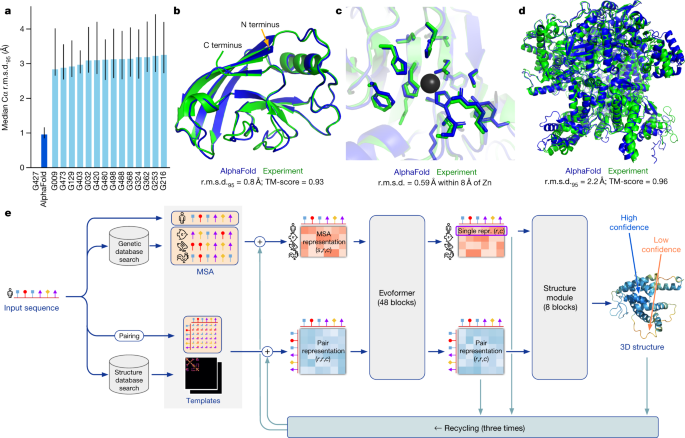
7. AlphaFold2开源
开源时间:2021年7月21日
项目地址:GitHub - deepmind/alphafold: Open source code for AlphaFold.
AlphaFold2虽然是去年的论文,但今年才公布源码。
亮点:
- 启发了其他团队在蛋白质预测方面的工作,例如启发了华盛顿大学蛋白质设计研究所主任大卫・贝克(David Baker)的团队研发出 RoseTTAFold 算法,这是一种计算成本更低的算法。RoseTTAFold和AlphaFold2是同一天开源的。
- 开源会极大促进新药研发,从而提高人类抗击疾病的能力。
知乎相关讨论:

8. 源1.0发布
发布时间:2021年10月10号
论文地址:Yuan 1.0: Large-Scale Pre-trained Language Model in Zero-Shot and Few-Shot Learning
亮点:
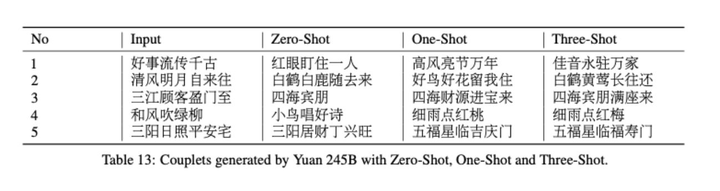
- 当了一天的的全球最大的NLP巨量模型(刚好下一天,MT-NLG发布了,笑死)
- 在零次学习和小样本学习里取得不错的效果,甚至在ZeroCLUE零样本学习榜和FewCLUE均拿下了除了人类之外的第一的成绩。(FewClue后被其他模型超过,太卷了)
知乎相关讨论:

9. MT-NLG
发布时间:2021年10月11号
亮点:
- 参数高达5300亿,是最大的单体模型。
- 根据英伟达的博客介绍,MT-NLG在完成预测(Completion prediction)、阅读理解(Reading comprehension)、常识推理(Commonsense reasoning)、自然语言推论(Natural language inferences)、词义消歧(Word sense disambiguation)这几个方面都取得了「无与伦比」(unmatched)的成就。

知乎相关讨论:

10. NÜWA:(女娲)
发布时间:2021年11月24日
论文地址:NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
亮点:
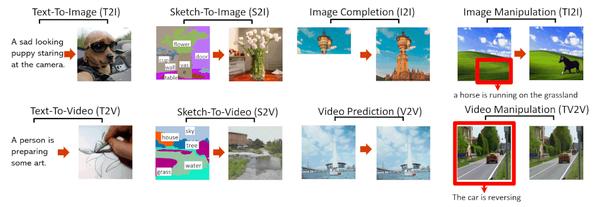
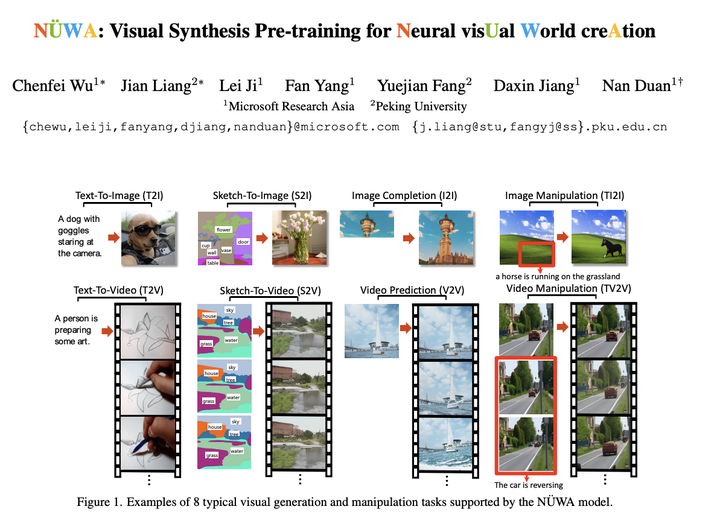
- NÜWA模型支持的8种典型视觉生成任务,分别是文字生成图像,文字生成视频,草图生成图像,草图生成视频,图像补全,视频预测,图像操控,视频操控
- 彩色的论文标题也是够皮的(咋滴,标题也卷起来了?)
知乎相关讨论:
Model of the Year
这是我在写文章时突发奇想加的一节内容。如果要提名个年度最有意思的模型,大家会选哪个呢?
那我个人会给MLP-Mixer。事实上,我和小伙伴们给这个模型的评分都挺高的。
尽管不是SOTA,但在今年好几个超大模型的情况下,另辟捷径,用回MLP,有种返璞归真的感觉。

总结
当然,仅仅列举十个AI成果还是不够的,我想尝试从这十个成果里总结几点今年人工智能发展的趋势:
- 堆叠模型参数依然有用,超大模型逐渐成为信息新基建的一部分,开始向开发者开放。(顺便一说,前面没说的是,但GPT-3上个月就向所有人开放了,其他超大模型也在慢慢开放中)
- CV和NLP继续融合(例如Swin Transformer,女娲)。
- 自监督的应用将更广泛。
除了上面列举的十个成果之外,今年还有很多其他不错的成果,例如2600亿参数的ERNIE 3.0 Titan,何恺明大神的Masked Autoencoders,等成果都不错,但怕超过10个大家看起来有压力,所以不展开写了了,感兴趣的可以搜搜看。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢