
在NeurIPS 2021上,RosettaCommons的Gray Lab团队展示了抗体预训练模型AntiBERTy,相对于AntiBERTa的参数量增加了10倍,并展示了如何用于分析抗体在体内的亲和成熟轨迹以及抗体CDR热点补位残基的预测效果。
论文链接:
https://arxiv.org/abs/2112.07782
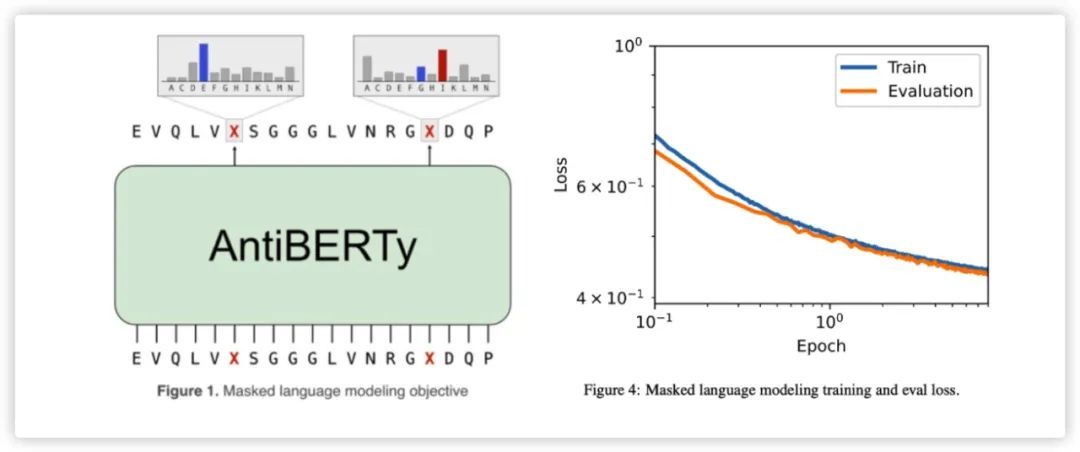
为了学习到抗体的表征,AntiBERTy采用了BERT构架,其中隐藏层维度为512,feedforward层为2048维,共计8层,每层8头注意力。共计约26M的参数量。以OAS数据库中约5.58亿条(95% training,5% testing)的自然抗体序列作为训练集,采用Mask Language Model的方式进行训练。共计训练8个epochs。
在后续分析抗体的亲和成熟轨迹,作者采用了多示例学习(Multiple instance learning)来分类预测一条抗体序列为binder的概率。由于免疫组库中的数据都是没有标签的数据,作者利用克隆扩增率和抗原结合直接的关系做为noisy label,假设那些出现频率高的抗体序列为binder,反之为non-binder。具体做法是将排名前85%富集的冗余序列标记为binder,其余为non-binder。每个bag从中随机采样64条序列来产生阳性样本或负样本的训练数据集。
MIL的构架分为两部分包括实例的Instance embedding和Bag classification两部分来进行弱监督式学习。Instance embedding中使用了attention注意力机制将维度压缩至1x32维。在Bag classification中使用gated attention对64条Instance embedding进一步池化,最后接上2层的NN来预测64条序列(Bag)的label标签,使用的是交叉熵训练了20个epochs。特别注意的是,训练使用的bag中binder和non-binder的采样频率是均等的。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢