
据作者称,这是第一个研究将语义上下文添加到预训练的Transformer主干以进行语义分割任务的效果,并提出SeMask,可插入现有分层ViT中,表现SOTA!优于Mask2Former等,代码刚刚开源!

单位:PAIR, SHI Lab, UIUC等
代码:https://github.com/Picsart-AI-Research/SeMask-Segmentation
论文:https://arxiv.org/abs/2112.12782
在图像Transformer网络的编码器部分对预训练的主干进行微调一直是语义分割任务的传统方法。然而,这种方法忽略了图像在编码阶段提供的语义上下文。
本文认为,在微调的同时将图像的语义信息合并到预训练的基于分层Transformer的主干中可以显著提高性能。
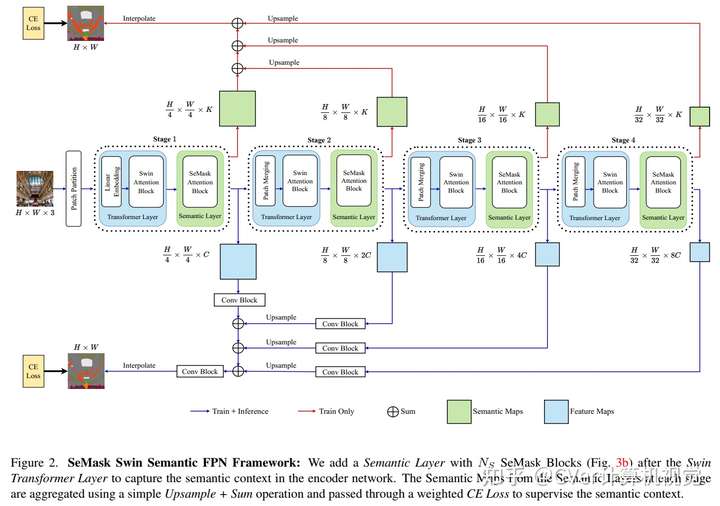
为了实现这一点,我们提出了 SeMask,这是一个简单而有效的框架,它在语义注意力操作的帮助下将语义信息合并到编码器中。
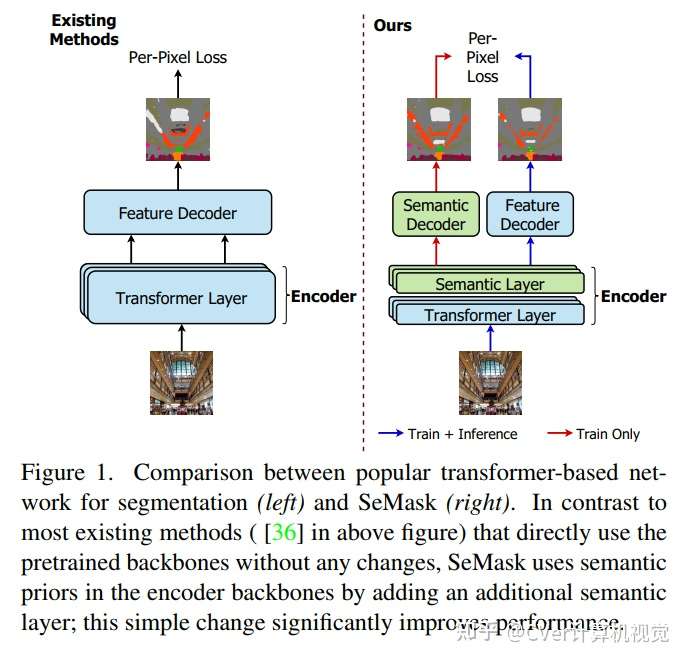
此外,我们在训练期间使用轻量级语义解码器来监督每个阶段的中间语义先验图。我们的实验表明,结合语义先验提高了已建立的分层编码器的性能,而 FLOPs 的数量略有增加。我们通过将 SeMask 集成到 Swin-Transformer 的每个变体中作为我们的编码器与不同的解码器配对来提供经验证明。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢