
【论文标题】DOCmT5: Document-Level Pretraining of Multilingual Language Models
【作者团队】Chia-Hsuan Lee, Aditya Siddhant, Viresh Ratnakar, Melvin Johnson
【发表时间】2021/12/16
【机 构】华盛顿大学、谷歌
【论文链接】https://arxiv.org/abs/2112.08709v1
本文介绍了DOCmT5,一个用大规模平行文档预训练的多语言序列对序列语言模型。虽然以前的方法主要是利用句子级的平行数据,但作者试图建立一个通用的预训练模型,可以理解和生成长文档。作者提出了一个简单有效的预训练目标--文档重排机器翻译(DrMT),其中需要翻译的是经过洗牌和屏蔽的输入文档。DrMT在各种文档级生成任务上比强大的基线带来了一致的改进,包括对看到的语言对文档级MT超过12个BLEU点,对未看到的语言对文档级MT超过7个BLEU点,对看到的语言对跨语言总结超过3个ROUGE-1点。作者在WMT20 De-En和IWSLT15 Zh-En文档翻译任务中取得了最先进的效果。作者还对文档预训练的各种因素进行了广泛的分析,包括预训练数据质量的影响和结合单语种和跨语种预训练的影响。
本文的主要内容是:
- 作者建立了一个最先进的多语言文档级序列对序列的语言模型,用结构感知的跨语言目标进行预训练。
- 作者提出的模型在跨语言总结和文档级机器翻译方面取得了强大的成果,包括WMT20 De-En和IWSLT2015 Zh-En任务的SOTA。
- 作者还进行了广泛的实验,研究在文档级多语言预训练中哪些有效,哪些无效。
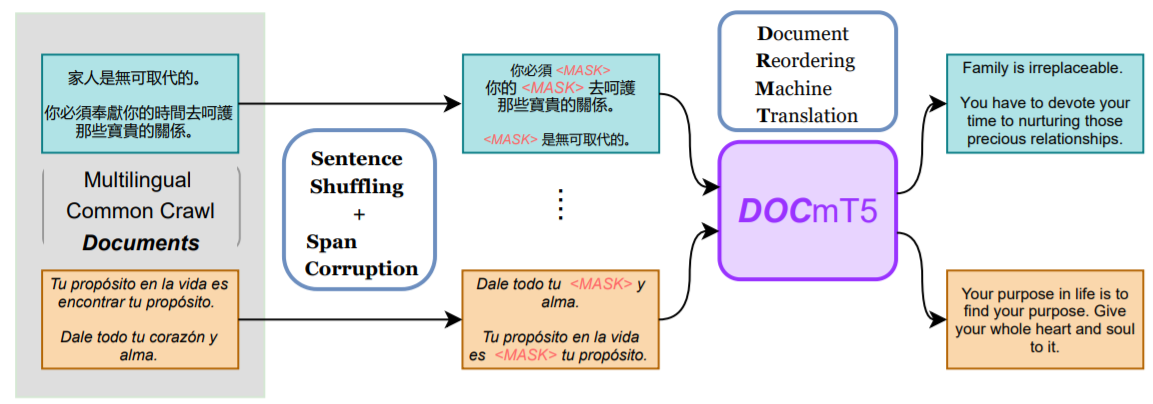
作者提出的Document-Reordering Machine Translation(DrMT)预训练概述。对于每个输入文件,句子以随机顺序进行重洗,然后随机选择的跨度将被屏蔽。DOCmT5的预测目标是生成输入文档的翻译。
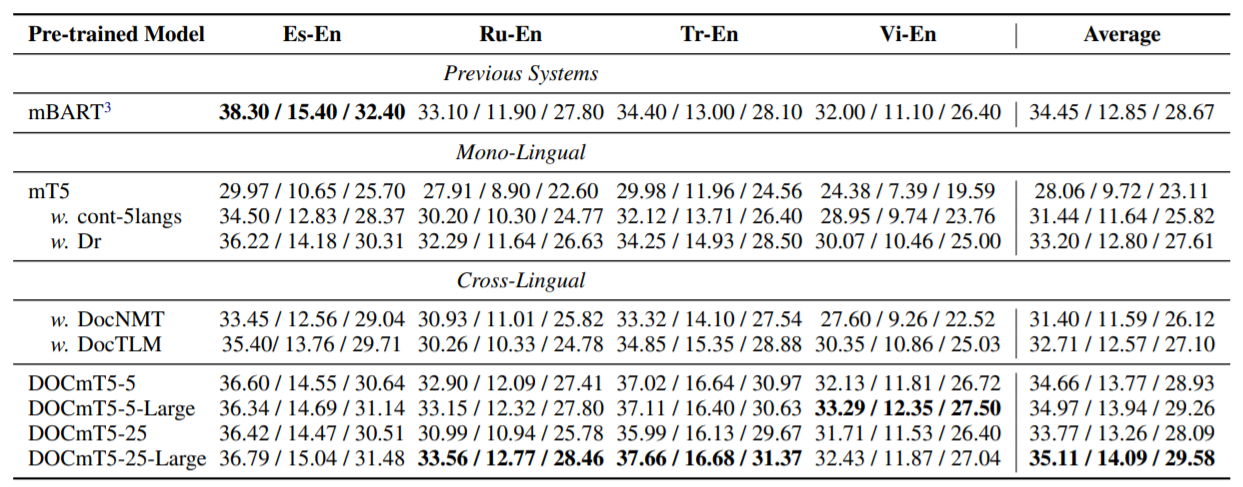
在Wikilingua上看到的四种语言{Es, Tr, Ru, Vi}的结果。每个单元格展示了三个指标。
作者使用的是Wikilingua原始版本中的四种语言。Dr目标在所有四种语言中都比cont-5langs带来了明显的改进,证明了结构感知目标的重要性。至于跨语言目标,除了俄语,DocTLM几乎在所有语言中都比DocNMT好。DOCmT5-5明显优于DocNMT和DocTLM,表明作者提出的预训练目标导致了跨语言学习的改进。DOCmT5-25的结果不如DOCmT5-5,这可能是由于容量稀释。随着作者增加容量,作者看到DOCmT5-25-Large优于DOCmT5-5-Large。DOCmT5-25-Large是整体表现最好的模型,超过了强先验系统:mBART。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢