
并行计算为了提高算法运行效率,本文通过以矩阵乘法(C = A * B)的各种实现思路以及优化方法总结为例子,过一遍cuda的几个基础优化策略。
代码链接:https://github.com/hova88/cuda-template
参照NVIDIA官网教程——https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/
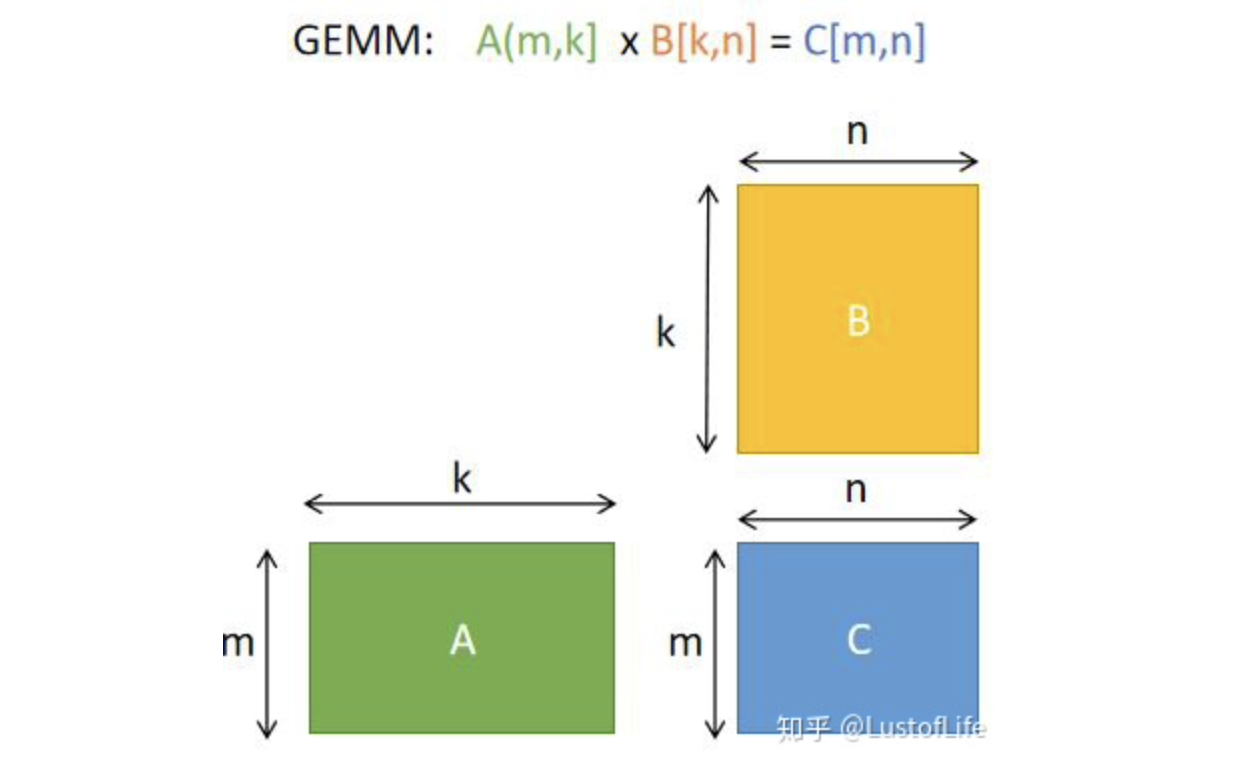
首先解决矩阵乘法问题更具体来说是解决GEMM(GEneral Matrix to Matrix Multiplication,通用矩阵乘法)问题。即C=αA*B+βC。其中A、B和C是矩阵。A是M×K矩阵,B是K×N矩阵,C是M×N矩阵。为了方便说明,后续的例子中假设标量alpha=beta=1。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢