
作者:Jianwei Yang, Pengchuan Zhang, 等
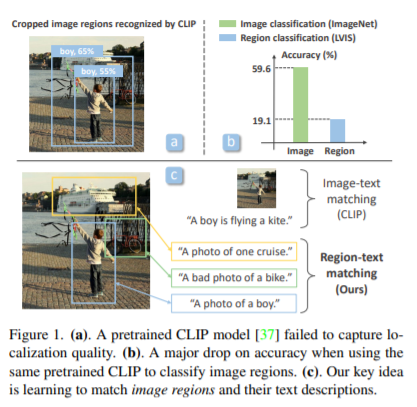
简介:本文研究基于识别图像区域的语言图像预训练模型。使用“图像-文本对”的对比语言图像预训练 (CLIP) 在零样本和迁移学习中的图像分类方面取得了令人印象深刻的结果。然而,作者表明直接应用此类模型来识别图像区域以进行对象检测会导致性能不佳,因为存在域偏移:CLIP 被训练以将图像作为一个整体与文本描述进行匹配,而没有捕获图像之间的细粒度对齐区域和文本跨度。为了缓解这个问题,作者提出了一种称为 RegionCLIP 的新方法,该方法显着扩展了 CLIP 以学习区域级视觉表示,从而实现图像区域和文本概念之间的细粒度对齐。作者的方法利用 CLIP 模型将图像区域与模板标题匹配,然后预训练作者的模型以在特征空间中对齐这些区域-文本对。当将作者的预训练模型转移到开放词汇对象检测任务时,作者的方法在 COCO 和 LVIS 数据集上的新类别分别显著优于现有技术 3.8 AP50 和 2.2 AP。此外,学习的区域表示支持对象检测的零样本推理,在 COCO 和 LVIS 数据集上都显示出良好的结果。
论文下载:https://arxiv.org/pdf/2112.09106.pdf
资源下载:https://github.com/microsoft/RegionCLIP
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢