
历史:
- 任务性质:合作和竞争(主要考虑)、mixed(实际中场景不是特别多)
- 方法分类:
- value-based/policy-based
- centralized/decentralized
- independent learning/joint learning


- CTDE(引出一系列值函数分解(近似)方法)
- 这篇文章讲的很详细 Jerry Chen:[伏羲讲堂]多智能体强化学习中的值函数分解——VDN、QMIX、QTRAN
- IQL
- 主要思想:IQL(independent Q-learning)就是非常暴力的给每个智能体执行一个Q-learning算法,
- 缺点:因为共享环境,并且环境随着每个智能体策略、状态发生改变,对每个智能体来说,环境是动态不稳定的,因此这个算法也无法收敛,但是在部分应用中也具有较好的效果。
- VDN
- 主要思想:VDN(value decomposition networks)也是采用对每个智能体的值函数进行整合,得到一个联合动作值函数。令
表示联合动作-观测历史,其中
为动作-观测历史,
表示联合动作。
为联合动作值函数,
为智能体i的局部动作值函数,局部值函数只依赖于每个智能体的局部观测。VDN采用的方法就是直接相加求和的方式
。虽然
- 缺点:由于VDN只是将每个智能体的局部动作值函数求和相加得到联合动作值函数,虽然满足联合值函数与局部值函数单调性相同的可以进行分布化策略的条件,但是其没有在学习时利用状态信息以及没有采用非线性方式对单智能体局部值函数进行整合,使得VDN算法还有很大的提升空间。

- QMIX
- 主要思想:QMIX就是采用一个混合网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助,来提高算法性能。为了能够沿用VDN的优势,利用集中式的学习,得到分布式的策略。主要是因为对联合动作值函数取
等价于对每个局部动作值函数取
因此分布式策略就是贪心的通过局部
获取最优动作。QMIX将(1)转化为一种单调性约束,如下所示
若满足以上单调性,则(1)成立,为了实现上述约束,QMIX采用混合网络(mixing network)来实现,其具体结构如下所示
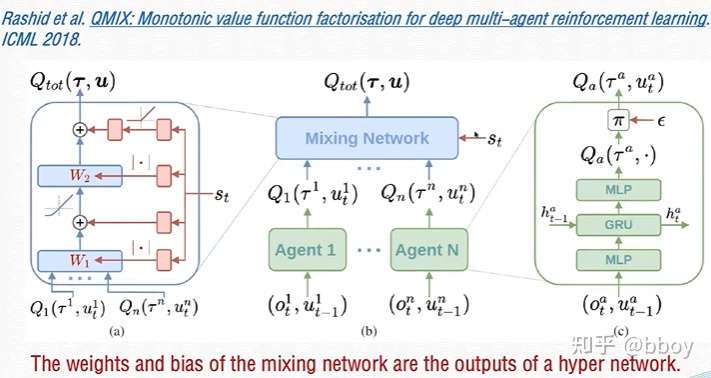
图(c)表示每个智能体采用一个DRQN来拟合自身的Q值函数的到 ,DRQN循环输入当前的观测
以及上一时刻的动作
来得到Q值。
图(b)表示混合网络的结构。其输入为每个DRQN网络的输出。为了满足上述的单调性约束,混合网络的所有权值都是非负数,对偏移量不做限制,这样就可以确保满足单调性约束。
为了能够更多的利用到系统的状态信息 ,采用一种超网络(hypernetwork),将状态
作为输入,输出为混合网络的权值及偏移量。为了保证权值的非负性,采用一个线性网络以及绝对值激活函数保证输出不为负数。对偏移量采用同样方式但没有非负性的约束,混合网络最后一层的偏移量通过两层网络以及ReLU激活函数得到非线性映射网络。由于状态信息
是通过超网络混合到
中的,而不是仅仅作为混合网络的输入项,这样带来的一个好处是,如果作为输入项则
的系数均为正,这样则无法充分利用状态信息来提高系统性能,相当于舍弃了一半的信息量。
QMIX最终的代价函数为
更新用到了传统的DQN的思想,其中b表示从经验记忆中采样的样本数量, ,
表示目标网络。
由于满足上文的单调性约束,对 进行
操作的计算量就不在是随智能体数量呈指数增长了,而是随智能体数量线性增长,极大的提高了算法效率。
- 缺点:我们知道VDN将Qtotal分解成所有Qi的累加和,QMIX将Qtotal分解成所有Qi的组成的单调函数。但是不管是累加性还是单调性,它们都其实严格限制了Qtotal与Qi之间的关系,从而使得它们只能解决一小部分任务,因为可能很多任务中Qtotal与Qi的关系不一定是累加或者单调,从而使得VDN和QMIX近似得到的Qtotal与真实的Qtotal相差很远,那么这样的更新是无用的。
- QTRAN
- 主要思想:QTRAN是直接学习一个Qtotal,同时创造了两个条件来约束Qtotal和Qi之间的关系,从而通过该关系去更新Qi。类似做法的还有最新的QPD ,DOP算法等等

- MADDPG
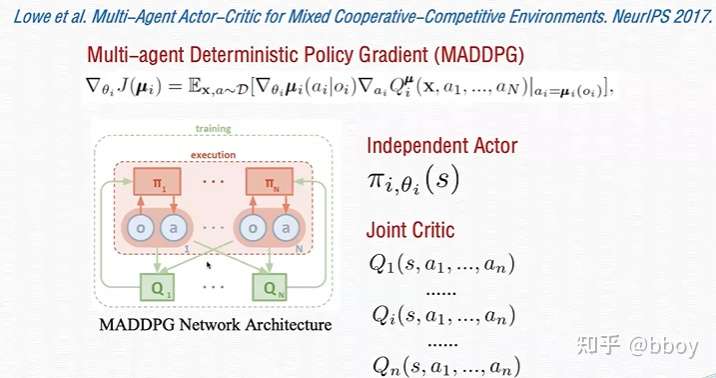
- MADDPG 算法将 DDPG 算法扩展到多智能体环境中,MADDPG 算法假定每一个智能体拥有自己独立的 critic network 以及 actor network,并且假定每个智能体拥有自己独立的回报函数,这样 MADDPG 算法就可以同时解决协作环境、竞争环境以及混合环境下的多智能体问题。但是 MADDPG 算法假定每个智能体在训练时都能够获取其余所有智能体的局部观察以及动作,因而即使每个智能体的 critic network 是独立的,训练时也需要中心化训练,因而遵循 CTDE 框架。
- 算法还进行了两点改进。其一,由于算法假设中心化训练每个智能体的 critic network 时,需要知晓所有智能体当前时间步的局部观察以及动作,本文认为知晓每个智能体的动作(即策略)是一个比较强的假设,因而提出了一个估计其余智能体 policy 的方法。具体来说,每个智能体均维护一个其余智能体 actor network 的估计,通过历史每个智能体的数据训练这个估计的 actor network。另外,在多智能体环境中,本文认为训练出的针对每个智能体的 policy 容易对其余智能体过拟合,但是其余智能体的 policy 随着训练过程的进行是不断更新的,因而本文希望通过给每个智能体同时训练 k 个 actor network 的方式,使得智能体对于其他智能体策略的变化更加鲁棒。具体来说,每个 episode 开始前,都从 k 个 actor 中随机采样一个来进行训练,并且每个 actor 都有独立的 experience replay。
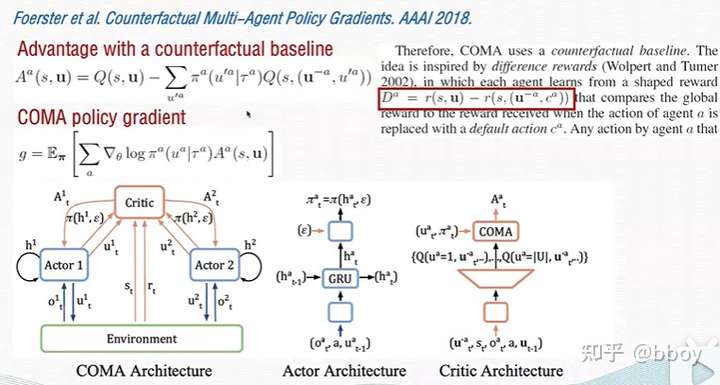
- COMA
- COMA 旨在解决 Dec-POMDP 问题中的 multi-agent credit assignment 问题,即多智能体信用分配问题。这个问题简单概括来说,由于 Dec-POMDP 问题中所有智能体共享同一个全局回报,因而每个智能体不知道自己的行为到底对这个全局回报产生了多大的影响,这就是多智能体信用分配问题。
- COMA 算法与 MADDPG 一样,遵循 CTDE 训练框架,但是因为解决的是 Dec-POMDP 问题,所以所有的智能体共享一个联合的 critic network,该 network 与 MADDPG 一样,基于所有智能体的局部观察以及动作,但是 actor network 是独立的并且只基于局部观察。COMA 与 MADDPG 在 actor network 上的不同之处在于前者使用的是 GRU 网络,为了更好的处理局部观察问题,但是后者使用的则是普通的 DNN。COMA 算法具体框架如下图所示:COMA 使用的是 vanilla 的 actor-critic 方法,其核心之处在于引入了一个 counterfactual 的 baseline 函数。这个思路是受到 difference rewards 方法启发的。该方法通过比较智能体遵循当前 actor network 进行决策得到的全局回报与遵循某个默认策略进行决策得到的全局回报,来解决多智能体信用分配问题。但是这种方法包括以下几个问题:
- 由于需要知道遵循某个默认策略得到的全局回报,需要重复访问仿真环境;
- 该默认策略得到的回报可能并不在仿真器的建模之中,因而需要进行估计;
- 该默认策略的选取是完全主观的。
- COMA 算法通过使用联合的 critic 来去计算每个智能体独自的优势函数来解决上述问题,该优势函数计算的是智能体遵循当前 actor network 进行决策得到的全局回报与一个反事实 baseline 之间的差值,这个反事实 baseline 通过求得该智能体 Q-value 的期望值得到,即:

- coordination
- 此类工作并不显式地学习智能体之间的通信,而是将 multi-agent learning 领域的一些思想引入到 MARL 中。而这类方案又可以分为以下三个类别:
- 基于值函数的方法(值函数分解):VDN、Qmix、QTran
- 基于演员-评论家的方法:MADDPG、COMA
- 对比:将单智能体强化学习算法扩展到多智能体环境中,最简单就是 IQL 类别方法,但是此类方法在复杂环境中无法处理由于环境非平稳带来的问题;另一方面,虽然中心化方法能够处理上述问题,但是与 IQL 相比又失去了较好的可扩展性。前面介绍的基于 value-based 方法通过 value decomposition 方式来解决可扩展性问题,那么对于基于演员-评论家方法,由于其结构的特殊性,我们可以通过中心化学习(共享/独立)评论家但是每个智能体独立的演员,来很好的处理算法可扩展性问题的同时,拥有很好的抗环境非平稳能力。
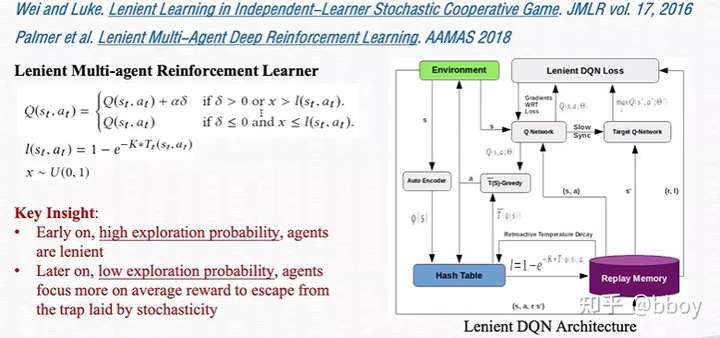
- 基于经验回放缓存的方法:主要聚焦于使用 ER 训练 Q-function 时增加稳定性(CommNet 甚至因为 ER 在 multi-agent 环境下的不稳定性而禁用了 ER),这两个方法前者遵循 CTDE 框架,并且类似 MADDPG 方法一样,均假设每个智能体拥有自己独立的 Q-function;后者则是完全独立的 IQL。这两个方法都是基于 Q-Learning 算法。Omidshafiei, Shayegan, et al. 的工作致力解决 partial observation 的问题,因而采用的是 DRQN 算法,本文提出采用 ER 训练 DRQN 时应当采用如下方式,并提出了 concurrent experience replay trajectories 的概念(图片来源原论文):

- communication
- 这一类别的多智能体强化学习方法显式假设智能体之间存在信息的交互,并在训练过程中学习如何根据自身的局部观察来生成信息,或者来确定是否需要通信、与哪些智能体通信等等。在训练完毕后运行的过程中,需要显式依据其余智能体传递的信息来进行决策。

什么时候、和谁、传哪些信息
什么情况下通信有必要 : 部分可观察

这篇文章最先在深度多智能体强化学习中引入通信学习,其解决的强化学习问题是 Dec-POMDP 问题。换句话说,在 Dec-POMDP 中,所有智能体共享一个全局的回报函数,所以是一个完全协作环境,每个智能体只拥有自己的局部观察。文中假设通信信道是离散的,即智能体之间只能能传递离散的信息(即 one-hot 向量)。
本文采用的是 CTDE 框架(即中心化训练去中心化执行,Centralized Training Decentralized Execution),在训练时不对智能体之间的信息传递进行限制(由于是中心化的训练器,所以智能体之间的信息传递完全由这个训练器接管),甚至在训练时可以使用连续的信息。但是训练完毕之后运行时,智能体之间才进行真正的通信,并且该通信信道是离散(如果训练时是连续的,则在运行时要对信息进行离散化)的。本文提出了两种算法,后一种是前一种的改进版本,具体名称陈列如下:
- Reinforced Inter-Agent Learning (RIAL)
- Differentiable Inter-Agent Learning (DIAL)
下面对这两种算法分别讨论。RIAL由于本文限定通信信道是离散的,因而 RIAL 算法将生成的信息也作为一个离散的动作空间来考虑,并设定信息的维度为 ,并且原始的动作空间的维度为 。RIAL 算法将 DRQN 算法与 IQL 算法结合起来,并显式在智能体之间传输可学习的信息来增加智能体对于环境的感知,从而解决 IQL 面临的因为环境非平稳所带来的性能上的问题。但如果只使用一个 Q network,那么总的动作空间的维度就是 。为了解决这一问题,RIAL 算法使用了两个 Q-network,分别输出原始的动作以及离散的信息。并且 RIAL 算法中 Q network 的输入不仅仅是局部观察,还包括上一时间步其余智能体传递过来的信息。另外还需提及的一点是,在多智能体环境中,采用 Experience Replay 反而会导致算法性能变差。这是因为之前收集的样本与现在收集的样本,由于智能体策略更新的原因,两者实际上是从不同的环境中收集而来,从而使得这些样本会阻碍算法的正常训练。也有许多工作解决这一问题,但由于本文时间较早,因而只是简单的禁用 Experience Replay,但这将大大降低算法的数据有效性。
虽然 RIAL 算法可以在智能体之间共享参数,但它仍然没有充分利用中心化训练的优势。而且,智能体不会互相提供,有关其接收到的信息的发送方智能体的通信行为的反馈。然而人类交流富有紧密的反馈循环。例如,在面对面互动时,听众会向发言者反馈一些非语言信息(例如眼神,微动作等),表明理解和兴趣的程度。RIAL 算法缺乏这种反馈机制,但是后者对于通信学习是非常重要的。所以本文在 RIAL 的基础上提出了一种新的算法 DIAL,该算法通过通信信道讲梯度信息从信息接收方传回到信息发送方。具体来说,在中心化训练时,信息发送方的信息动作输出直接连接到信息接收方,并且为了能够实现端到端训练,此时的信息将不再是离散值而是连续值。训练完毕之后执行时,通过这个实值的正负进行 one-hot 离散化。其具体算法框架如上图所示。同时为了增加算法的鲁棒性,这个信息实值是从一个拥有固定方差的高斯分布中采样而来,该分布的均值即信息发送方生成的实值。
- CommNet
- 本文假设智能体之间传递的消息是连续变量(不像 RIAL 或者 DIAL 是离散的),文章采用的强化学习算法应该是 policy gradient 方法(论文本身没有指明,这个结论是从网络结构上推断而出)。本文解决的也同样是 Dec-POMDP 问题,遵循的是中心化训练中心化执行 CTCE(Centralized Training Centralized Execution)框架,因而在大规模的多智能体环境下,由于网络输入的数据维度过大,会给强化学习算法的训练带来困难。

- 该框架中所有灰色模块部分的参数均是所有智能体共享的,这一定程度上提升了算法的可扩展性。从上图可以看出,算法接收所有智能体的局部观察作为输入,然后输出所有智能体的决策(其实整个框架有一点图神经网络的意思,这里使用的聚合函数就是 mean 函数,然后整个图是一个星状图)。本算法采用的信息传递方式是采用广播的方式,文中认为可以对算法做出些许修改,让每个智能体只接收其相邻 个智能体的信息。拿上图中间的框架图来说明,即上层网络每个模块的输入,不再都是所有智能体消息的平均,而是每个模块只接受满足条件的下层消息的输出,这个条件即下层模块对应的智能体位于其领域范围内。这样通过增加网络层数,即可增大智能体的感受野(借用计算机视觉的术语),从而间接了解全局的信息。除此之外,文中还提出了两种对上述算法可以采取的改进方式:
- 可以对上图中间的结构加上 skip connection,类似于 ResNet。这样可以使得智能体在学习的过程中同时考虑局部信息以及全局信息,类似于计算机视觉领域 multi-scale 的思想
- 可以将灰色模块的网络结构换成 RNN-like,例如 LSTM 或者 GRU 等等,这是为了处理局部观察所带来的 POMDP 问题
- BicNet
- 算法基于演员-评论家算法框架,使用的是 DDPG 算法,并且考虑到算法在大规模多智能体环境下的可扩展性问题,智能体之间共享模型参数,并且算法假设每个智能体都拥有同样的全局观察(全局状态),这也是本文的局限之一。另外,BiCNet 同样遵循 CTCE 框架。
- 策略网络(参与者)和Q网络(批评者)(参与者和批评者都是双向rnn)都基于双向RNN结构。双向递归结构不仅可以用作通信通道,还可以用作本地内存保护程序(双向rnn起的作用双向交流,而且有记忆存储功能),每个单独的代理都可以维护自己的内部状态,并与其协作者共享信息。

- network design

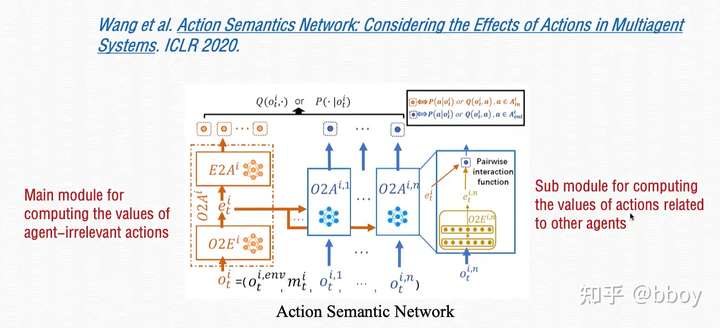
- ASN 解决目标选择的问题
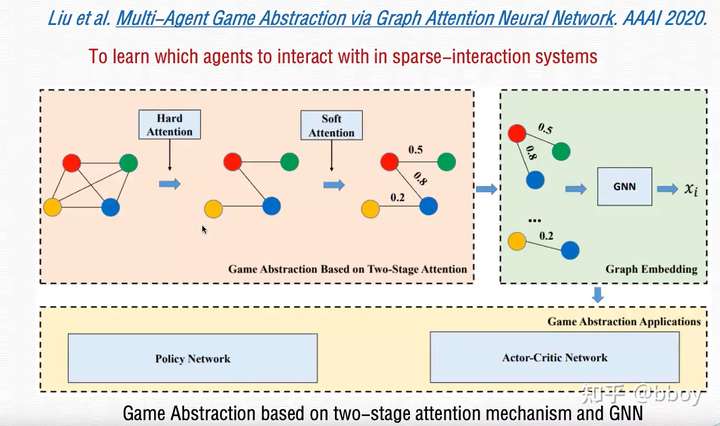
- 支持可变数量agent的训练
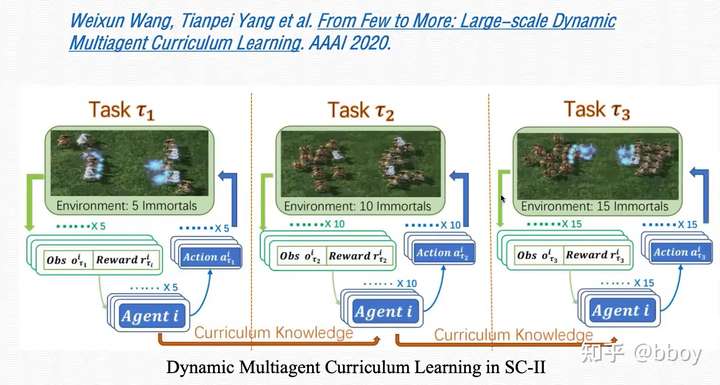
- exploitation



- multiagent exploitation


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢