
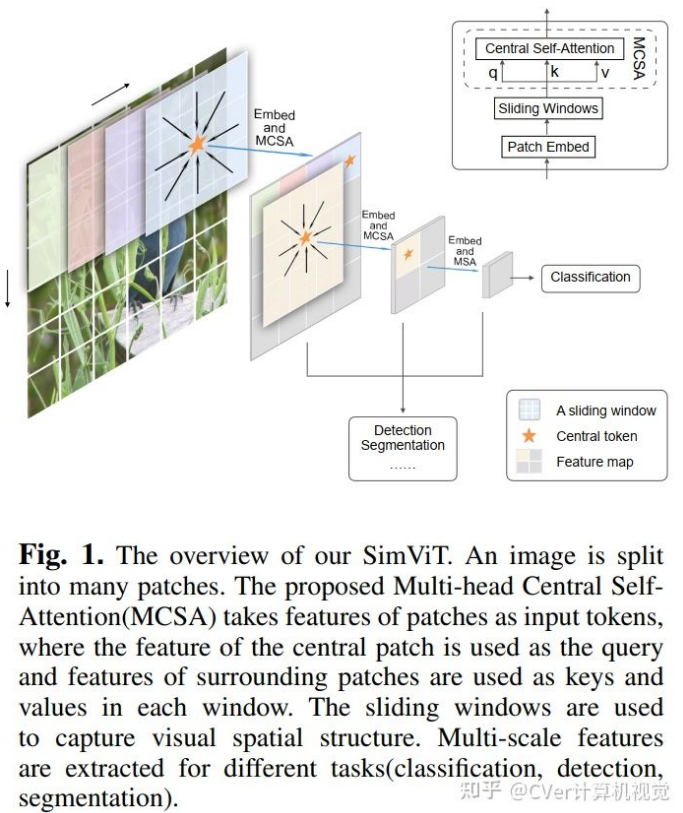
本文提出了一种名为SimViT的简单而有效的视觉Transformer,它使用多头中央自注意力(MCSA)和简单的滑动窗口将空间结构和局部信息集成到ViT中,同时多尺度层次特征可以应用于各种密集预测视觉任务,代码将开源!

单位:中科院, 国科大
代码:https://github.com/ucasligang/SimViT
论文:https://arxiv.org/abs/2112.13085
尽管视觉Transformer在许多视觉任务中作为主干模型取得了出色的性能,但它们中的大多数都打算捕获图像或窗口中所有token的全局关系,这破坏了二维结构中patch之间固有的空间和局部相关性。
在本文中,我们介绍了一个名为 SimViT 的简单视觉 Transformer,将空间结构和局部信息整合到视觉 Transformer 中。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢