
本文重点介绍了下小样本学习方法(FSL)演变过程以及MAML和度量学习的区别所在。
小样本学习一般会简化为N-way K-shot问题,如图[1]。其中N代表类别数量,K代表每一类中(支持集)的样本量;

解决分类问题,人们最先想到的是采用传统监督学习的方式,直接在训练集上进行训练,在测试集上进行测试,如图[2],但神经网络需要优化的参数量是巨大的,在少样本条件下,几乎都会发生过拟合;

为了解决上述问题,人们首先想到的是通过使用迁移学习+Fine-tune的方式,利用Base-classes中的大量数据进行网络训练,得到的Pre-trained模型迁移到Novel-classes进行Fine-tune,如图[3]。虽然是Pre-trained网络+Fine-tune微调可以避免部分情况的过拟合问题,但是当数据量很少的时候,仍然存在较大过拟合的风险。

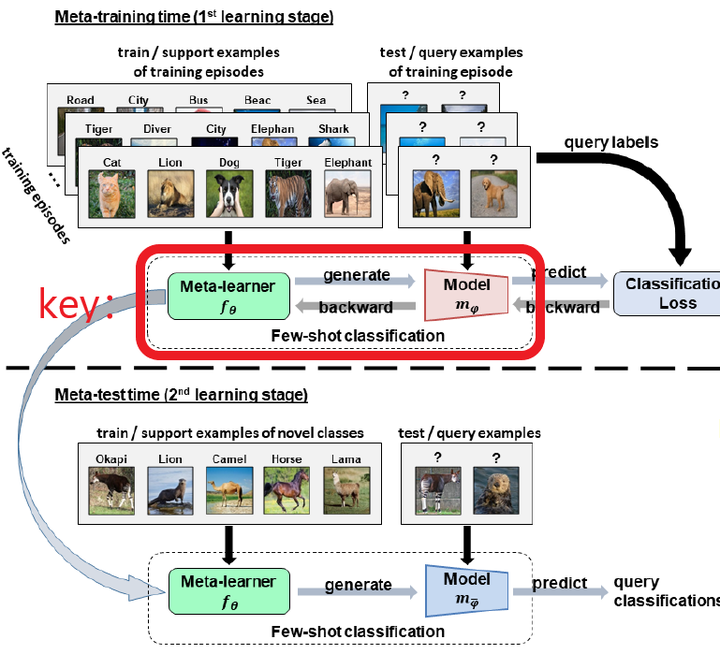
接下来讲的就是小样本学习中极具分量的Meta-learning方法,现阶段绝大部分的小样本学习都使用的是Meta-learning方法。Meta-learning,即learn to learn,翻译成中文是元学习。Meta-learning共分为Training和Testing两个阶段,Training阶段的思路如图[4]。简单描述下流程:
1:将训练集采样成Support set和Query set两部分;
2:基于Support set生成一个分类模型 ;
3:利用模型对Query set进行分类预测生成predict labels;
4:通过query labels和predict labels进行Loss(e.g., cross entropy loss )计算,从而对分类模型 中的参数θ进行优化。

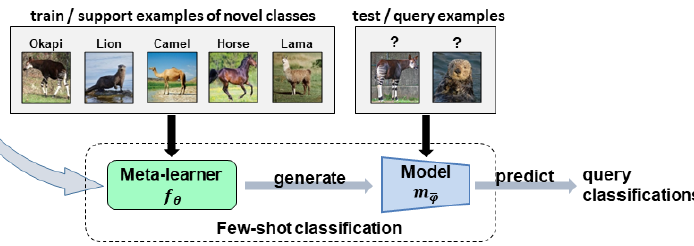
Testing阶段的思路如图[5],利用Training阶段学来的分类模型 在Novel class的Support set上进行进一步学习,学到的模型对Novel class的Query set进行预测。
介绍到这里,Meta-learning的整体流程的流程就介绍完了,如图[6];
现在反过来看,Meta-learning核心点之一是如何通过少量样本来学习这个 这个分类模型,即图[6]中的key部分。在这里引出了Meta-learning的两个主要方法:度量学习(Matrix-based Meta-learning)和MAML(Optimization-based Meta-learning),本文简要介绍了二者的原理以及在处理小样本问题时的优缺点:
首先介绍下度量学习(Metric Learning):度量学习是一种空间映射的方法,其能够学习到一种特征(Embedding)空间,在此空间中,所有的数据都被转换成一个特征向量,并且相似样本的特征向量之间距离小,不相似样本的特征向量之间距离大,从而对数据进行区分。
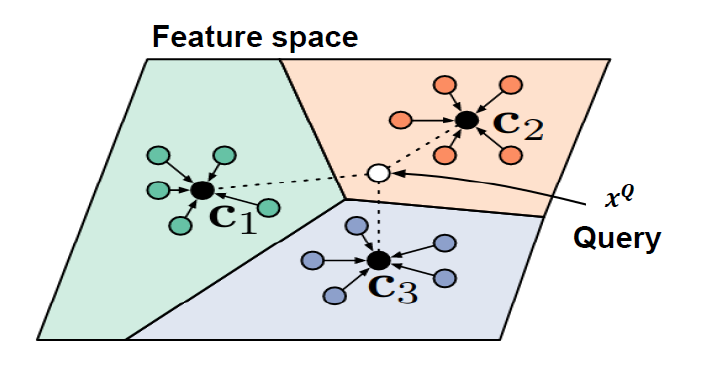
以经典的原型网络Prototypical Networks为例,如图[7]:将Support set投影到一个度量空间,且在这个空间中同类样本距离较近,异类样本的距离较远。为了对Query set中的X进行预测,则将样本X投影至这个空间并计算X距哪个类别较近,则认为X属于哪个类别。
Meta-learner这一步采用度量方法的好处是:在生成 这个阶段不需要进行参数优化。ps:度量方法的思想来自机器学习算法(KNN,K-means,最近邻等算法)。距离通常使用欧氏距离和cos距离,深度度量学习主要的关键点是损失函数的设计。损失函数相关可以参考https://zhuanlan.zhihu.com/p/82199561,本文不重点介绍。
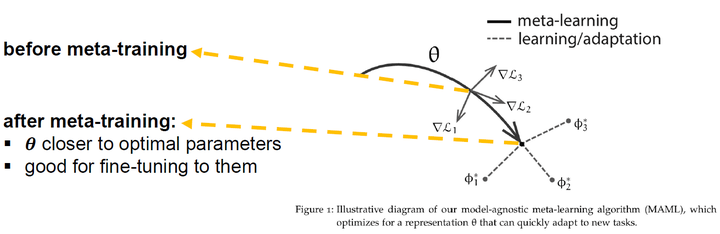
接下来介绍下MAML(Model-Agnostic Meta-Learning)方法:与度量学习 使用度量方法构建不同,MAML采用的是
梯度下降优化方法。如图[8].
MAML的优点:
1:与标准的fine-tuning 方法一致,2:Model-agnostic: 适用于各种网络backbone.
MAML的缺点:
相比度量学习的投票方式,MAML需要学习的参数量更多,需要更多的算力;另外由于这个原因也导致没有办法训练大型网络;与其说MAML是为了解决小样本问题而生的,不如说MAML更适用于小样本学习问题。
最后想补充两点自己对元学习的理解:
1:元学习是通过优化loss来拟合query data,使得模型来逐渐适应这种小样本的学习方式;
2:从参数优化的角度来讲,模型学习的是一个通用的初始化参数,使得再遇到新任务时,通过训练可以快速收敛到最优解。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢