
几周前,安德烈·库伦科夫 (Andrey Kurenkov) 写道“GPT-3 不再是城里唯一的游戏”,其中讨论了自 OpenAI 模型发布以来出现的大型预训练语言模型。 12 月,《麻省理工科技评论》将 2021 年称为“超大 AI 模型年”。其中包括来自中国、韩国和以色列的语言和多模态模型。在这篇文章中,作者将讨论这些模型在人工智能正成为世界各国政府日益重要的国家优先事项的世界中的作用。
在他 2018 年的作品“人工智能民族主义”中,天使投资人伊恩霍格沃斯描述了一种趋势,即“机器学习的持续快速进步将推动一种新型地缘政治的出现。” GPT-3 发布后,来自不同国家的大型语言模型的堆积几乎就像一场地缘政治驱动的竞赛,在这场竞赛中,“国家冠军”——OpenAI、华为或 DeepMind 等人工智能人才的高度集中中心——开发出更强大的模型。尽管迄今为止这些大型模型主要由私人组织开发,没有政府参与,但它们在特定国家/地区的发展仍然可以对该国在全球人工智能领域的地位做出巨大贡献。此外,这些模型的发展至少部分归功于各国建立的人工智能生态系统,以及国家层面投资的潜在动力。作者将集中讨论这两个方面——各国开发自己的“超大模型”的雄心,以及为什么这在这些模型的直接应用之外在国家层面上很重要。
模型扩散和模型开发
从“人工智能民族主义”文章中提出的角度来看,GPT-3 对世界来说是一个令人难以置信的声明:迄今为止开发的最强大的深度学习模型在美利坚合众国大放异彩。开发人员和公众很快注意到了 GPT-3 的无数功能——它可以让训练模型来解决语言任务对于没有深厚专业知识的开发人员来说变得更加容易——而且多家初创公司甚至开始在 GPT-3 之上构建产品。语言并不是唯一取得进步的领域:GPT-3 紧随其后的是 CLIP 和 DALL-E,后者使用其架构来支持图像生成。毫不奇怪,其他国家,尤其是中国,往好里说是挑战,往坏了说是威胁;斯坦福大学关于“基础模型”的报告——诸如 GPT-3 之类的模型,这些模型“在大规模数据上进行了训练,因此可以适应广泛的下游任务”——将它们描述为具有潜在的同质化效果,这意味着他们将整合跨不同应用程序构建机器学习系统的方法,并引入单点故障。
因此,基础模型的创建者将凭借其模型对下游用户的影响而发挥相当大的影响力和权力——并且这些用户很可能会被激励在他们的应用程序中使用这些基础模型,因为这样的模型易于适应 特定任务,而不是从头开始开发新模型。 如果太多的基础模型驻留在美国,其他国家可能会任由美国摆布:美国开发商的决定和错误将在世界范围内产生影响。 多个国家和私人参与者开发 GPT-3 风格的 AI 模型的现象被前 OpenAI 政策主管 Jack Clark 称为模型扩散,他认为这是“历史进程中的普遍趋势...... 工具。”
GPT-3 发布一年半后,作者们看到来自多个大国的参与者加入竞争,尤其是在 2021 年下半年:
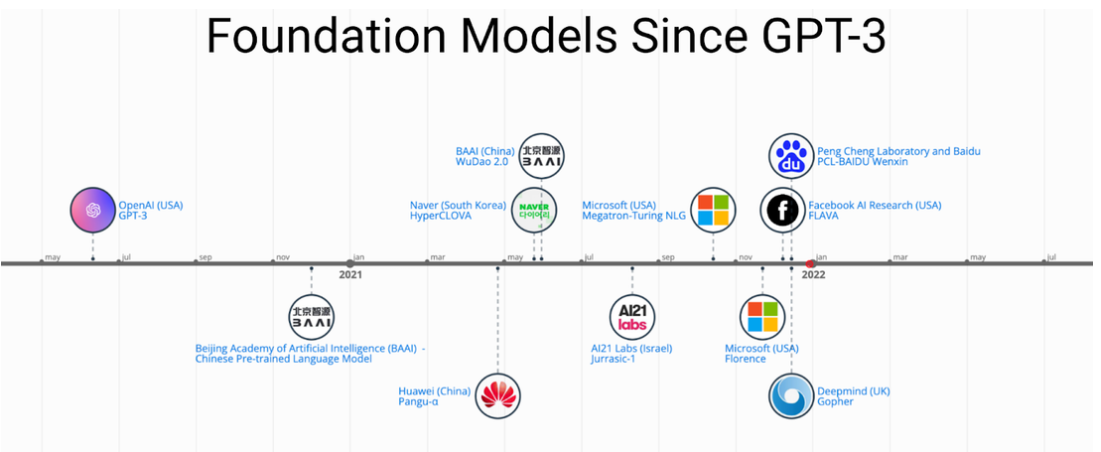
- 北京智源人工智能研究院(BAAI)发布CPM
- 华为(中国)发布盘古-α
- Naver(韩国)推出 HyperCLOVA
- 北京智源人工智能研究院发布悟道2.0
- AI21 Labs(以色列)宣布侏罗纪-1
- 微软研究院(美国)宣布Florence
- Facebook AI Research(美国)推出 FLAVA
- DeepMind(英国)宣布 Gopher
- 鹏程实验室与百度(中国)发布PCL-百度文心
参考
https://lastweekin.ai/p/gpt-3-foundation-models-and-ai-nationalism
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢