
【标题】Efficient Performance Bounds for Primal-Dual Reinforcement Learning from Demonstrations
【作者团队】Angeliki Kamoutsi, Goran Banjac, John Lygeros
【发表日期】2021.12.28
【论文链接】https://arxiv.org/pdf/2112.14004.pdf
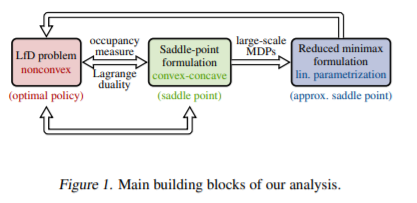
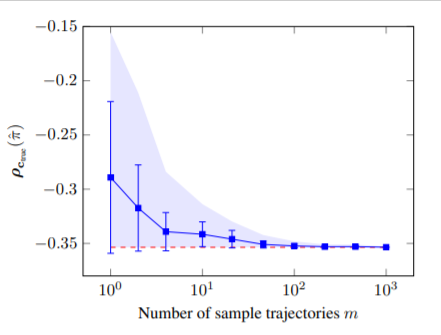
【推荐理由】本文考虑了具有未知成本函数的大规模马尔可夫决策过程,从一组有限的专家演示中解决学习策略的问题。并假设学习者不被允许与专家互动,也无法获得任何形式的强化信号。现有的逆强化学习方法具有强大的理论保证,但计算成本较高,而最先进的策略优化算法取得了显著的经验成功,但受到理论理解的限制。为了弥合理论和实践之间的鸿沟,通过引入了一种基于拉格朗日对偶的双线性鞍点框架。所提出的原始-对偶观点允许本文通过随机凸优化的视角开发一个无模型的可证明有效的算法。该方法具有实现简单、内存需求低、计算和样本复杂度与状态数无关等优点。该研究进一步提供了一个等效的无悔在线学习解释。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢