作者:Zi-Yi Dou,Nanyun Peng
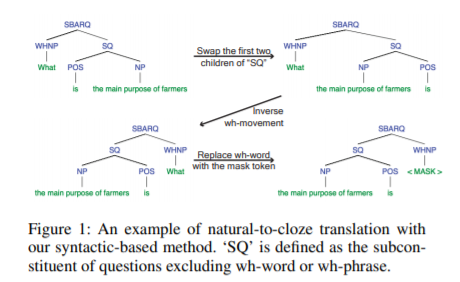
简介:本文研究预训练的语言模型中的知识提取、聚焦在常识问答(CQA)方向。在本文中,作者将重点放在更好地利用预训练语言模型中存储的知识。虽然研究人员发现,通过让预训练语言模型填充精心设计的关系提取和文本分类提示的空白,可以提取嵌入在预训练的语言模型中的知识,但目前尚不清楚是否可以在CQA中采用这种范式(其输入和输出的形式更加灵活)。作者研究了四种可以将自然问题翻译成完形填空式句子的翻译方法,以更好地从语言模型中获取常识性知识。实验证明了作者的方法在三个CQA数据集上的有效性,以及作者的方法是对知识库改进模型的补充、可以获得小样本最先进的性能。分析还揭示了不同完形填空翻译方法的不同特点,并提供了将它们结合起来可以带来巨大改进的观点建议。
论文下载:https://arxiv.org/pdf/2201.00136.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢