
主要思路和创新点
本文针对场景中的文本识别,架构依然基于 Transformer,但有趣的是在输出文本特征后还会进一步整合两个阶段的特征。最前面阶段平平凡凡,就是针对图片的编码器和提前设定的文本解码器:
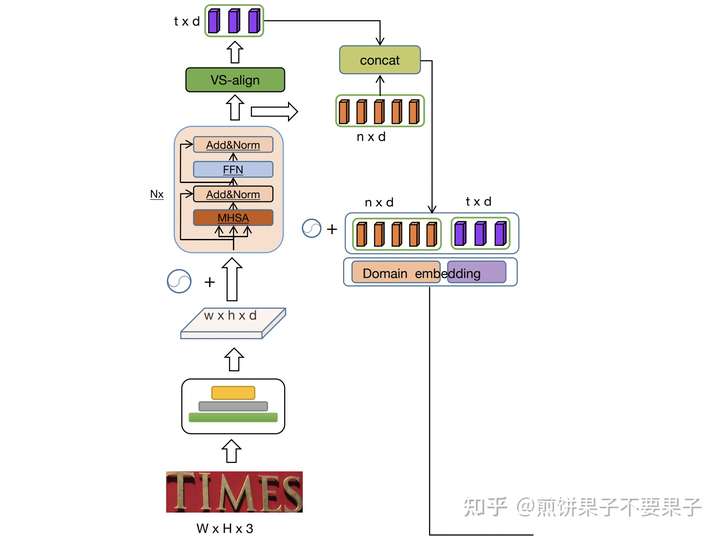
特征提取的骨架网络采用 ResNet 结构,之后特征图输入和 Transformer 编码器一样的结构优化特征,而图片中的 VS-align 和 Transformer 解码器结构有一点差别。紫色为希望输出的文本特征,序列长度为 t,这部分结构为:
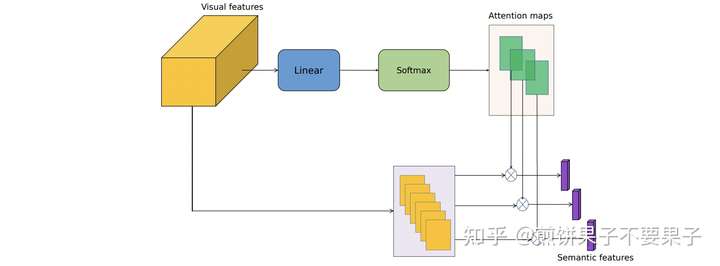
这里其实可以视作解码器的简化版本,Q / K / V 均不需要经过一个线性映射就参与计算。这里可以将初始目标序列 Q 视作一个对 K 的线性映射,即上面分支,看公式可能就比较清楚了:

之后,预测的文本特征会和视觉特征连在一起,分别进行相应的位置编码作为接下来的输出。视觉特征采用固定版本(盲猜 sinusoidal?),而文本特征则采用可学习编码。连接起来的特征整体输入又一个编码器,再进行一波特征优化:
公式可以表达为:
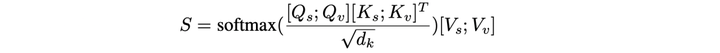
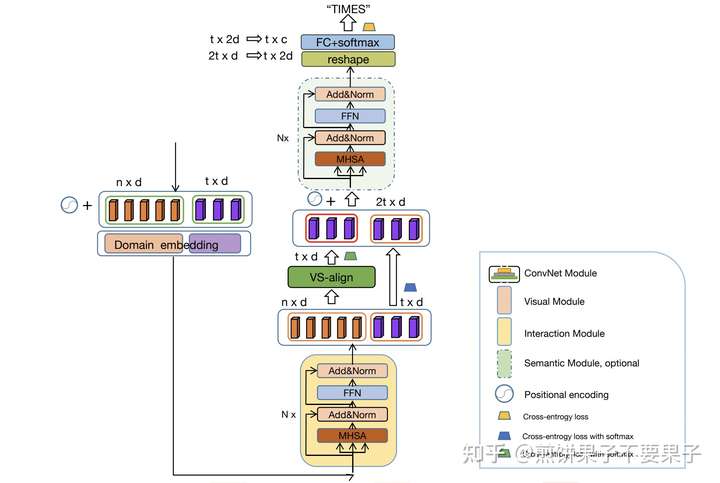
之后,优化后特征的文本部分可以通过类别预测作第一个交叉熵损失了,即上图中间右边的紫色部分。视觉特征则通过又一个 VS-align 预测该阶段的文本特征,这个 VS-align 模块是和前面的参数共享,以此增强语义信息的学习能力。模块的输出又可以通过类别预测进行第二个交叉熵损失了,这部分图片画的很清楚,两阶段文本特征连在一起再使用编码器优化,输出特征更改一下形状,即将左右两个序列叠加在一起预测第三个交叉熵损失。
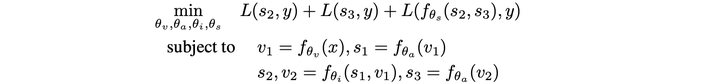
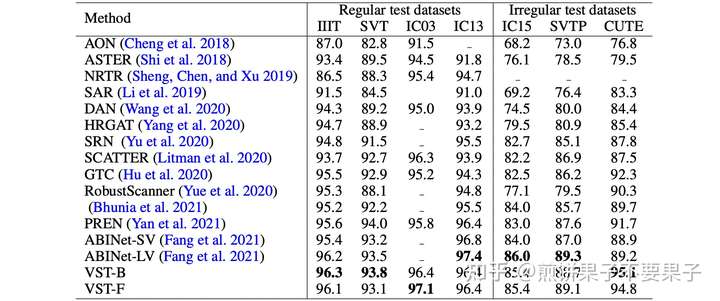
实验结果和可视化

论文信息
Visual-Semantic Transformer for Scene Text Recognition
论文链接:https://arxiv.org/pdf/2112.0094
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢