
最近,通过视觉语言预训练的零样本图像分类已经展示了令人难以置信的成就,即模型可以对任意类别进行分类,而不需要看到该类别的额外注释图像。然而,目前还不清楚如何使零样本识别在更广泛的视觉问题上运作良好,如物体检测和语义分割。本文以零样本语义分割为目标,将其建立在一个现成的预训练的视觉语言模型上,即CLIP。该问题难点在于语义分割和CLIP模型在不同的视觉颗粒度上执行,语义分割在像素上处理,而CLIP在图像上执行。为了弥补处理粒度上的差异,本文拒绝使用普遍的基于FCN的单阶段框架,而提倡一个两阶段的语义分割框架,第一阶段提取可概括的掩码建议,第二阶段利用基于图像的CLIP模型,对第一阶段产生的掩码图像作物进行零点分类。本文的实验结果表明,这个简单的框架在很大程度上超过了以前的先进技术。在Pascal VOC 2012数据集上+29.5 hIoU,而在COCO Stuff数据集上+8.9 hIoU。凭借其简单性和强大的性能,本文希望这个框架能够作为一个基线来帮助未来的研究。
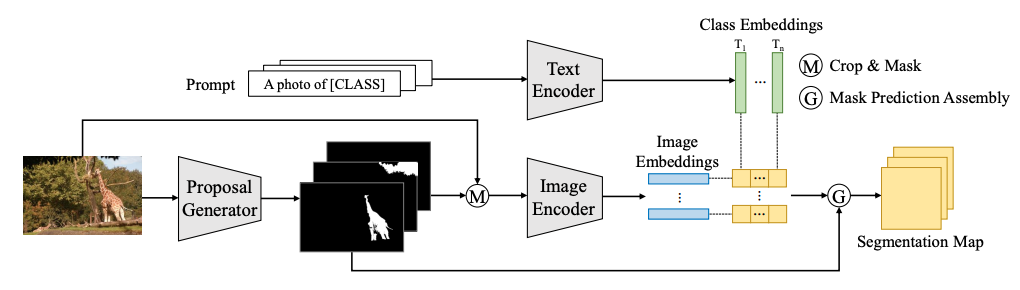
上图展示了两阶段零样本语义分割框架。作者重新制定并将零样本语义分割分解为两个步骤:训练一个掩码建议生成器以生成一组二进制掩码,并利用预训练的CLIP对每个掩码建议进行分类。
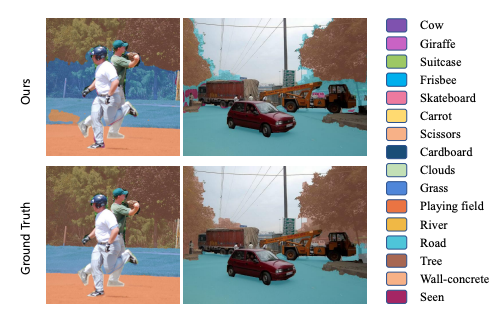
本文的方法对COCO Stuff数据集的定性结果。COCO Stuff是一个更具挑战性的基准,本文的方法仍然以很大的优势超越了先进的技术。具体来说,在不使用自训练的情况下,本文的方法取得了37.8 hIoU和36.3 mIoU-unseen的成绩,在hIoU和mIoU-unseen方面分别比之前最好的方法CaGNet高出了+19.5和+24.1。进一步采用自训练,本文的方法在hIoU上取得了41.5的成绩,在mIoU-unseen上取得了43.6的成绩,在hIoU上比以前最好的方法STRICT多了8.9,在mIoU-unseen上多了13.3。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢