
【论文链接】https://arxiv.org/abs/2112.15283v1
传统的图像-文本生成任务的方法主要是分别处理双向生成任务,重点是设计特定任务的框架来提高生成样本的质量和保真度。最近,视觉语言预训练模型极大地提高了图像-文本生成任务的性能,但用于文本-图像合成任务的大规模预训练模型仍未得到开发。本文提出了ERNIE-ViLG,一个统一的生成预训练框架,用于双向图像-文本生成的Transformer模型。基于图像量化模型,本文将图像生成和文本生成都表述为以文本/图像输入为条件的自回归生成任务。双向的图像-文本生成模型简化了跨视觉和语言的语义对接。对于文本到图像的生成过程,本文进一步提出了一种端到端的训练方法来共同学习视觉序列生成器和图像重建器。为了探索双向文本-图像生成的大规模预训练的前景,本文在1.45亿图像-中文文本对的大规模数据集上训练了一个100亿参数的ERNIE-ViLG模型,该模型在文本-图像和图像-文本任务上都取得了最先进的性能,在文本-图像合成的MS-COCO上获得了7.9的FID,在图像字幕的COCO-CN和AIC-ICC上取得了最佳结果。
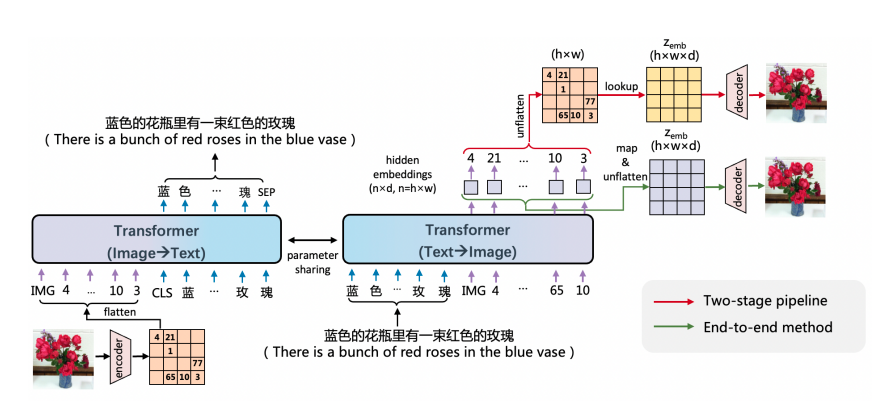
上图展示了ERNIE-ViLG的双向生成框架。图像通过矢量变分自动编码器(VQVAE)表示为一个离散的表征序列,被用作参数Tranformer的输入/输出,用于自回归图像-文本/文本-图像生成。具体来说,对于图像到文本的生成,Tranformer将图像离散序列作为输入,生成相应的文本序列。相反,对于文本到图像的合成,文本被输入到Tranformer以生成相应的视觉离散序列,然后图像离散序列被用于重建图像。除了传统的两阶段方法,本文进一步提出了一种端到端的训练方法,即联合训练离散表征序列生成和图像重建的模块,以加强文本到图像合成的能力。

ERNIE-ViLG已经获得了各种场景的生成能力,从基本物体到复杂的物体组合。ERNIE-ViLG不仅能画出给定文本描述中提到的实体,还能将它们与背景合理地结合在一起。令人惊讶的是,本文还发现ERNIE-ViLG开发了两种特殊技能。首先,ERNIE-ViLG可以通过简单地添加文字提示来生成不同风格的图像,而不像CogView那样进行微调。其次,如上图展示一样,本文的模型可以在给定的中国古诗词中生成现实的图像,这表明对简短和抽象描述的理解很有希望。诗歌中的真实概念组织得很好,艺术构思也描述得很好。

上图展示了零样本和微调的部分结果。零样本的ERNIE-ViLG模型获得了较高的流畅性分数,与微调模型接近,但它们之间的相关性分数和丰富性分数差距很大。本文认为这是由于网络抓取的预训练数据集往往是嘈杂的,大多数标题的描述性较低,而人类标记的标题数据集(如COCO-CN)中的标题往往是描述性的,捕捉了图像的所有细节。
综上,
本文提出了ERNIE-ViLG,一种用于双向图像-文本生成任务的统一的生成预训练方法,其中图像和文本生成都被表述为自回归生成任务。并且,本文提出了第一个基于图像离散表示的文本-图像合成的端到端训练方法,该方法同时增强了生成器和重建器,并优于传统的两阶段方法。
- 本文训练了一个100亿参数的ERNIE-ViLG模型,并在文本到图像和图像到文本的生成任务中获得了卓越的性能,在MS-COCO上为文本到图像合成设定了新的SOTA结果,并在两个流行的中国数据集上获得了图像字幕的SOTA结果。
- 在生成性VQA任务上的优异表现表明,本文的双向生成模型捕捉到了视觉和语言模态之间复杂的语义对接。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢