

近日,国际计算语言学协会 ACL 举办的 WMT 2021 国际机器翻译比赛的评测结果揭晓。由微软亚洲研究院、微软翻译产品团队及微软图灵团队联合发布的 Microsoft ZCode-DeltaLM 模型获得了 WMT 2021 「大规模多语言翻译」赛道的冠军。该模型基于微软亚洲研究院机器翻译研究团队打造的能支持上百种语言的多语言预训练模型 DeltaLM,在微软 ZCode 的多任务学习框架下进行训练生成。研究员们希望能够借助该多语言翻译模型,有效支持更多低资源和零资源的语言翻译,终有一日实现重建巴别塔的愿景。
项目链接:https://github.com/microsoft/unilm
预训练一个语言模型通常需要很长的训练时间,为了提高 DeltaLM 的训练效率和效果,微软亚洲研究院的研究员们并没有从头开始训练模型参数,而是从先前预训练的当前最先进的编码器模型(InfoXLM)来进行参数初始化。虽然初始化编码器很简单,但直接初始化解码器却有一定难度,因为与编码器相比解码器增加了额外的交叉注意力模块。因此,DeltaLM 基于传统的 Transformer 结构进行了部分改动,采用了一种新颖的交错架构来解决这个问题(如下图所示)。研究员们在解码器中的自注意力层和交叉注意力层之间增加了全连接层。具体而言,奇数层的编码器用于初始化解码器的自注意力,偶数层的编码器用于初始化解码器的交叉注意力。通过这种交错的初始化,解码器与编码器的结构匹配,可以与编码器用相同的方式进行参数初始化。
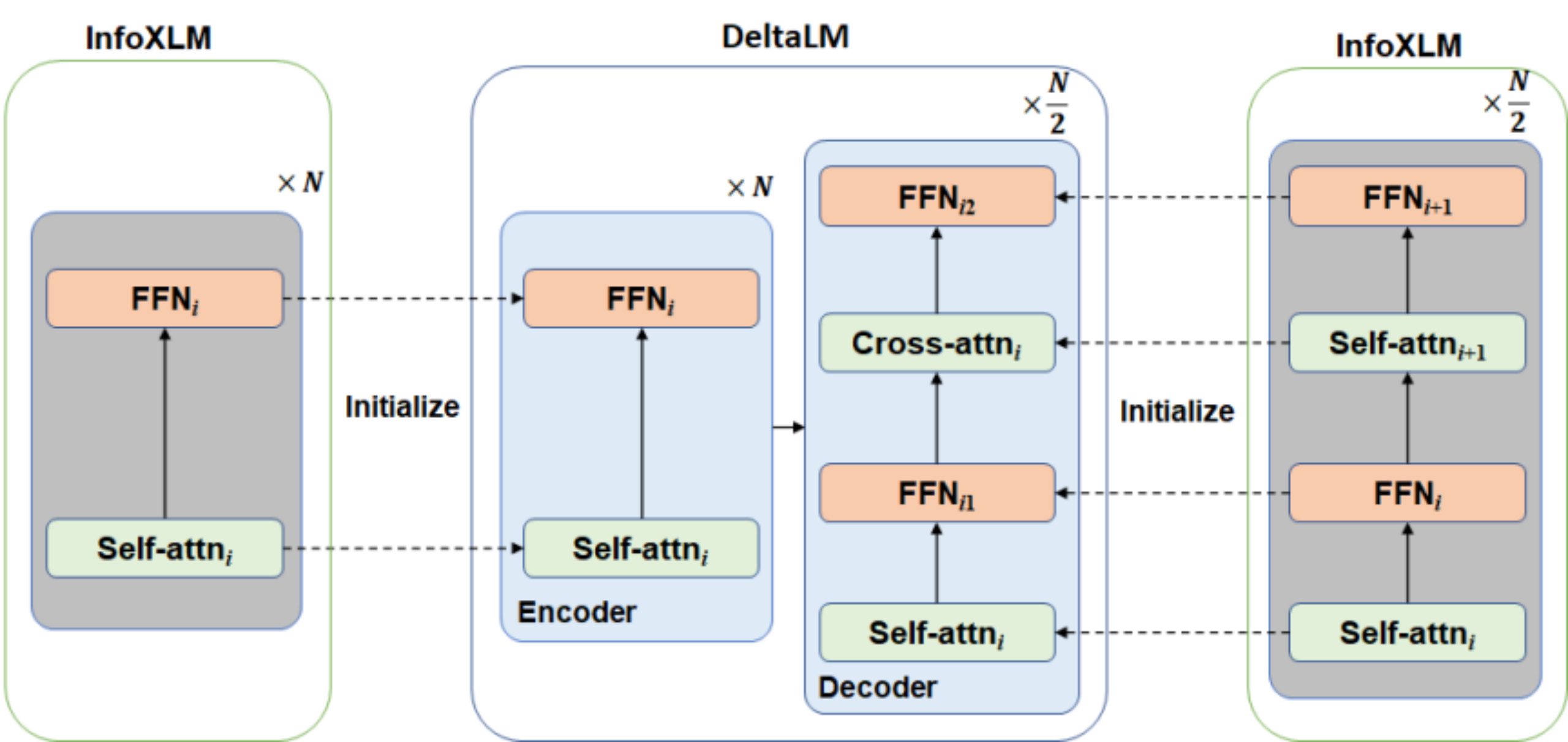 DeltaLM 模型结构及参数初始化方法示意图
DeltaLM 模型结构及参数初始化方法示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢