我将我对主动学习的理解和最新研究的感悟都整理为这篇文章,主要目的是供大家参考、讨论,一起学习和交流主动学习的技术。同时,我以后还会继续阅读主动学习领域的文章,有不错和值得推荐的文章,我会实时更新到我的 github 里,大家可以通过这个 list 最快地阅读最新最重要的文章,也欢迎大家向我推荐一些文章和一起交流。
主动学习是一种通过主动选择最有价值的样本进行标注的机器学习或人工智能方法。其目的是使用尽可能少的、高质量的样本标注使模型达到尽可能好的性能。也就是说,主动学习方法能够提高样本及标注的增益,在有限标注预算的前提下,最大化模型的性能,是一种从样本的角度,提高数据效率的方案,因而被应用在标注成本高、标注难度大等任务中,例如医疗图像、无人驾驶、异常检测、基于互联网大数据的相关问题。
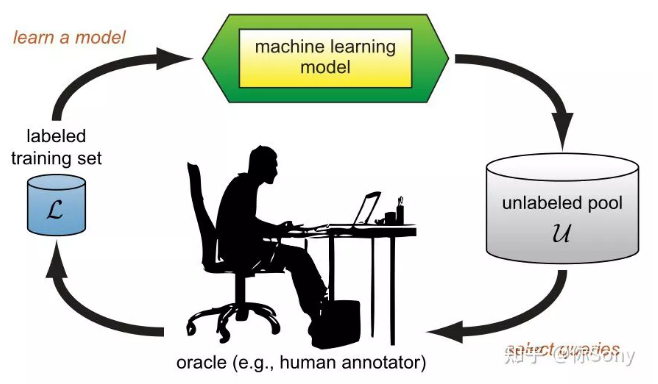
Settles, Burr 的 Active Learning Literature Survey 文章为经典的主动学习工作进行了总结。上图是经典的基于池的主动学习框架。在每次的主动学习循环中,根据任务模型和无标签数据的信息,查询策略选择最有价值的样本交给专家进行标注并将其加入到有标签数据集中继续对任务模型进行训练。因为主动学习的过程中存在人的标注,所以主动学习又属于 Human-in-the-Loop Machine Learning 的一种。
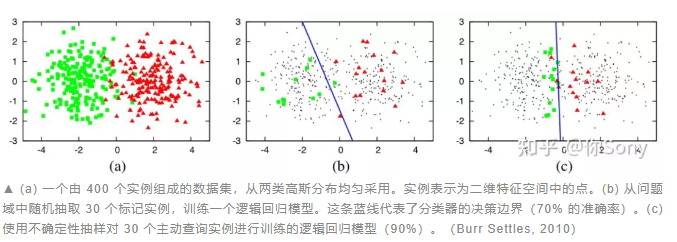
主动学习为什么是有用的?下面通过一个直观的小例子让大家感受一下。
由此说明,样本对模型的贡献并不是一样的,选择更有价值的样本具有实际意义。当然,如何确定和评估样本的价值也是主动学习研究的一个重点。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢