

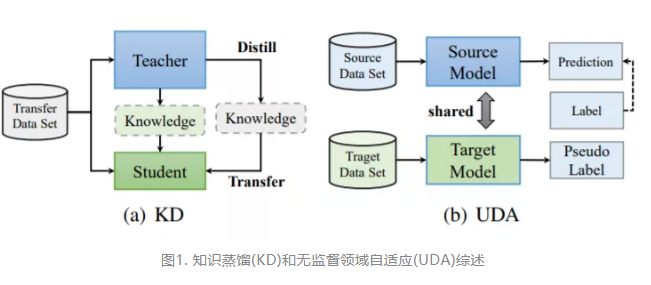
在过去的十年中,许多深度学习模型在机器智能的各个领域得到了良好的训练并取得了巨大的成功,特别是在计算机视觉和自然语言处理方面。为了更好地利用这些训练有素的模型在域内或跨域迁移学习情况下的潜力,知识蒸馏(KD)和域自适应(DA)被提出并成为研究热点。它们的目的都是利用原始的训练数据从训练有素的模型中传递有用的信息。然而,在许多情况下,由于隐私、版权或机密性,原始数据并不总是可用的。最近,无数据知识迁移范式引起了人们的关注,因为它处理的是从训练有素的模型中提取有价值的知识,而不需要访问训练数据。它主要包括无数据知识蒸馏(DFKD)和无源数据领域适应(SFDA)。一方面,DFKD的目标是将原始数据的域内知识从一个繁琐的教师网络转移到一个紧凑的学生网络中,进行模型压缩和高效推理。另一方面,SFDA的目标是重用存储在经过良好训练的源模型中的跨领域知识,并使其适应于目标领域。本文从知识蒸馏和无监督领域适应的角度对无数据知识迁移的研究进行了全面的综述,以帮助读者更好地了解目前的研究现状和思路。本文将分别简要回顾这两个领域的应用和挑战。在此基础上,对未来的研究提出了一些看法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢