
无监督的大规模视觉语言预训练在各种下游任务上显示出不错的进步。现有方法通常通过每个模态的全局特征的相似性来模拟跨模态交互,或者通过视觉和文本token的交叉/自注意力来模拟细粒度交互。然而,交叉/自注意力在训练和推理方面的效率较低。
在本文中,作者引入了大规模细粒度交互式语言图像预训练(FILIP),通过跨模态后期交互机制实现更细粒度的对齐,该机制使用视觉和文本标记之间的token最大相似度来指导对比目标。FILIP通过仅修改对比损失,成功地利用了图像块和文本词之间的细微表达能力,同时获得了在推理时预先计算图像和文本表示形式的能力,保持了大规模训练和推理效率。
此外,作者还构建了一个新的大规模图像-文本对数据集FILIP300M,用于预训练。实验表明,FILIP在多个下游视觉语言任务(包括Zero-shot图像分类和图像文本检索)上实现了SOTA的性能。单词-patch对齐的可视化进一步表明,FILIP可以学习有意义的细粒度特征,具有良好的定位能力。

论文地址:
https://arxiv.org/abs/2111.07783
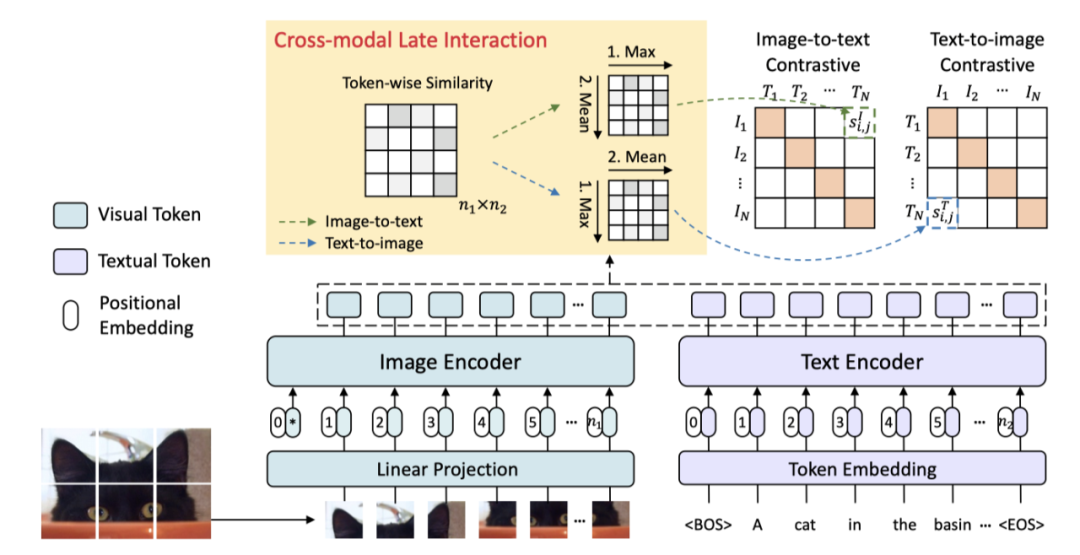
在本文中,作者提出了一个新的跨模态预训练模型,该模型在图像编码器和文本编码器之间的细粒度交互中表现出色,用于挖掘更详细的语义对齐,FILIP的结构如上图所示。FILIP是一个双流模型,带有基于Transformer的图像和文本编码器。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢