作者:Xiaofeng Yang,Fengmao Lv,等
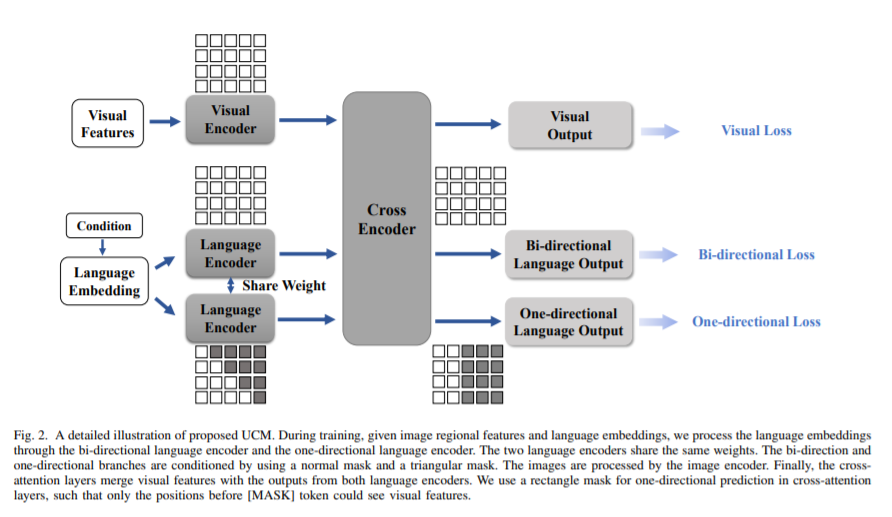
简介:本文研究视觉语言BERT类模型的自训练新方法并获得显著效果。与自然语言BERT模型不同,视觉语言BERT类的模型(VL-BERT)需要视觉与语言的成对数据进行训练,这限制了VL-BERT预训练的规模。作者提出了一种自训练方法、允许从未标记的图像数据中训练VL-BERT。具体如下:(1)基于统一条件模型,作者提出一个可以执行小样本条件生成的视觉语言BERT模型。(2)在不同的条件下,统一条件模型可以生成:字幕、密集字幕、甚至问题。(3)作者使用标记的图像数据来训练教师模型,并使用预训练后的模型在未标记的图像数据上生成伪字幕。(4)然后作者结合标记数据和伪标记数据来训练学生模型。该过程通过将学生模型作为新教师进行迭代。实验表明:使用该自训练方法和仅300k未标记的数据,与使用300万图像数据训练的类似大小的模型相比,作者获得了具有竞争力甚至更好的性能。

论文下载:https://arxiv.org/pdf/2201.02010
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢