
文章题目:
Visual Entity Linking via Multi-modal Learning
作者:郑秋硕,闻浩,王萌,漆桂林
论文链接:
现有的视觉场景理解方法主要关注识别视觉对象及检测视觉关系,其侧重于粗粒度概念发现,而忽略了细粒度场景理解。事实上,网络上的许多数据驱动应用场景(例如新闻阅读和电子购物)需要准确地将概念提及识别为实体,并正确地链接到知识图谱。有鉴于此,本文确定了一项新的研究任务:用于细粒度场景理解的可视化实体链接。为了完成这项任务,我们首先从不同的模态中提取候选实体的特征,即视觉特征、文本特征和知识图谱特征。然后,我们设计了一种基于深度模态注意力的神经网络,利用排序学习方法,将所有特征集合起来,并将视觉提及映射到知识图谱中的实体。
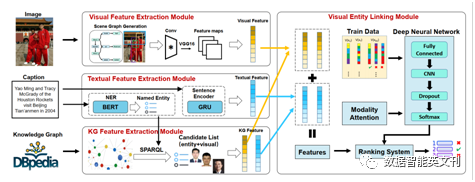
图2.视觉实体链接概述,它由两部分独立组成,即特征提取模块和视觉实体链接模块。特征提取模块从三种模式中提取特征。
在本文中,我们提出了一个新的框架来实现视觉场景理解中的视觉实体链接。具体地说,我们首先为图像生成一个粗粒度的场景图,并利用VGG-16网络提取对象的视觉特征。然后,我们使用GRU语言方法从图像标题中提取对象的文本特征,并通过命名提及匹配发现候选KG实体。在提取候选实体的KG特征后,我们提出了一种基于深度模态注意神经网络的学习排序方法来聚合所有特征并将视觉对象映射到KG中的实体。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢