
【标题】Sample Efficient Deep Reinforcement Learning via Uncertainty Estimation
【作者团队】Vincent Mai, Kaustubh Mani, Liam Paull
【发表日期】2022.1.5
【论文链接】https://arxiv.org/pdf/2201.01666.pdf
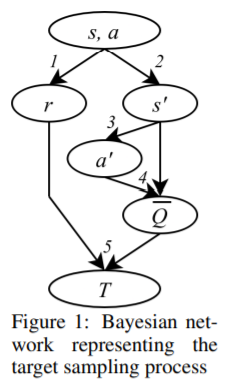
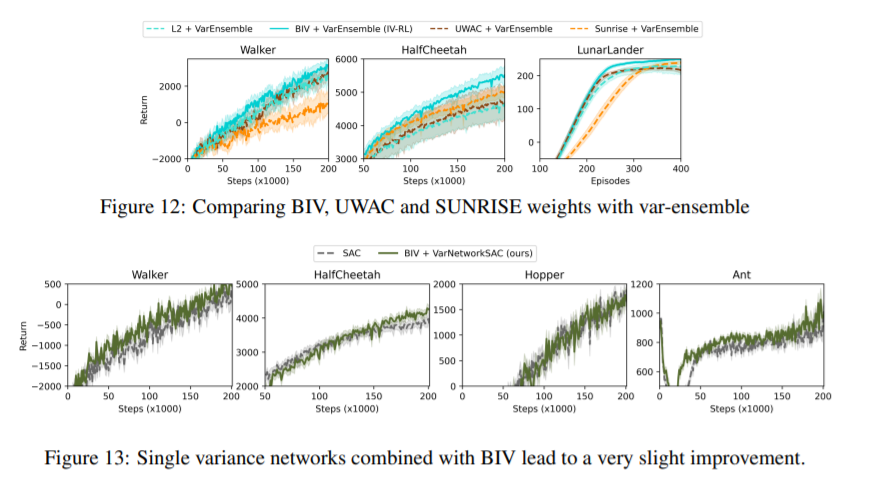
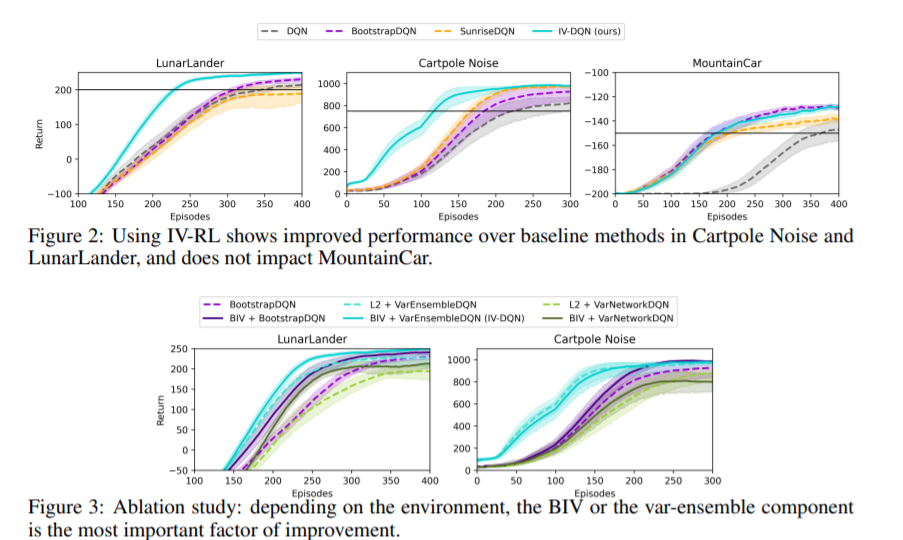
【推荐理由】在无模型深层强化学习(RL)算法中,使用噪声值估计来监督策略评估和优化会对样本效率造成不利影响。由于这种噪声是异方差的,因此可以在优化过程中使用基于不确定性的权重来缓解其影响。先前的方法依赖于抽样的集合,这些集合不能捕获不确定性的所有方面。本文通过对RL中出现的噪声监督中的不确定性来源进行系统分析,并引入了反向方差RL,这是一种结合概率集合和批量反向方差加权的贝叶斯框架。本文提出了一种方法,其中两种互补的不确定性估计方法同时考虑了Q值和环境随机性,以更好地缓解噪声监督的负面影响。研究结果表明,在离散和连续控制任务中,样本效率显著提高。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢