
【标题】A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning
【作者团队】Xueguang Lyu, Andrea Baisero, Yuchen Xiao, Christopher Amato
【发表日期】2022.1.3
【论文链接】https://arxiv.org/pdf/2201.01221.pdf
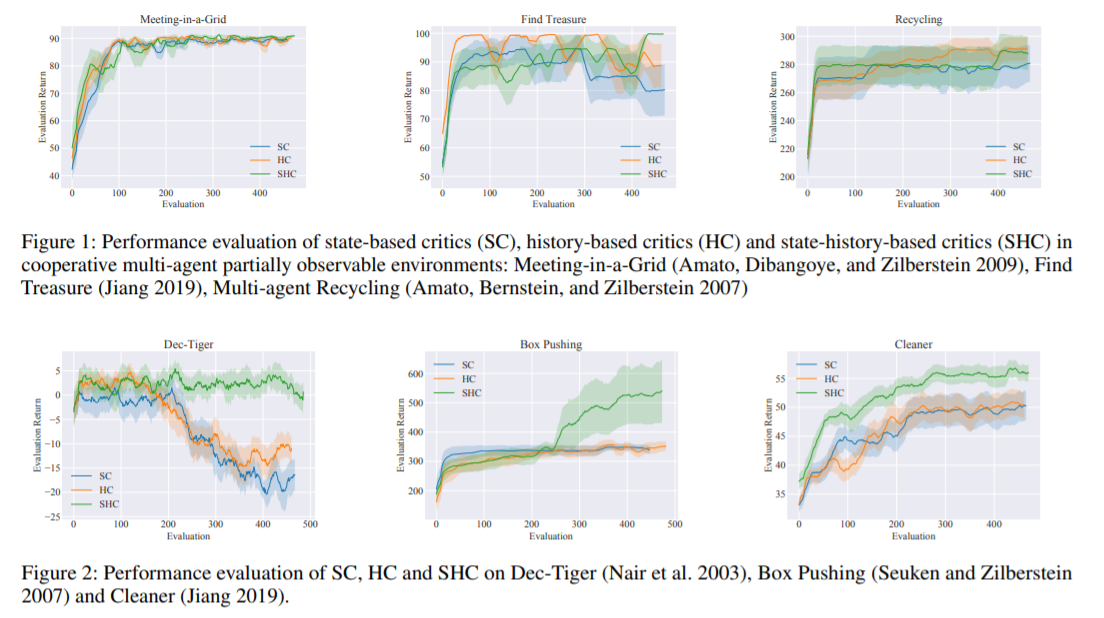
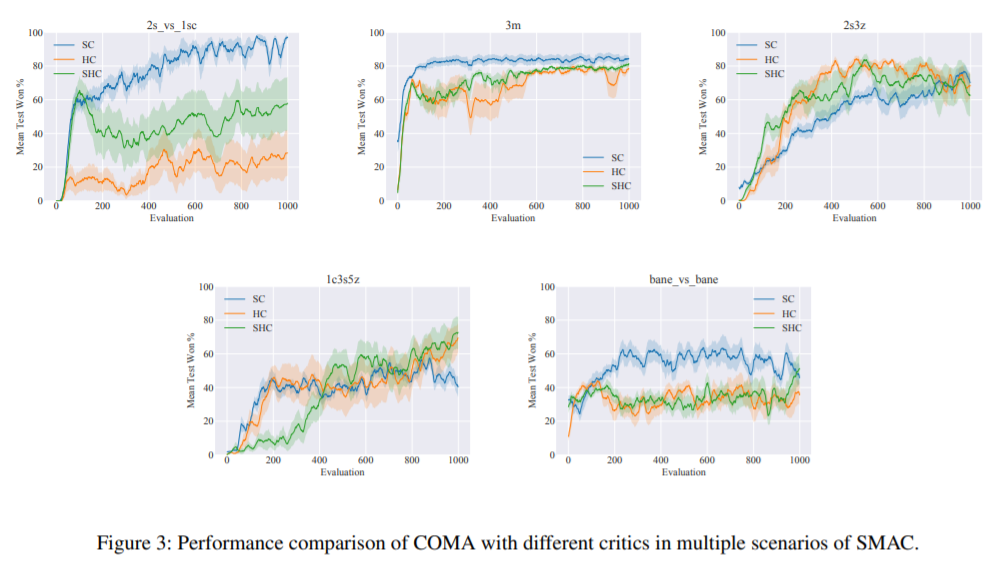
【推荐理由】分散执行的集中训练,即以集中的离线方式进行训练,已成为多智能体强化学习中流行的解决方案范例。许多此类方法采用基于状态的批评者的参与者批评者的形式,因为集中式训练允许访问真实的系统状态,尽管在执行时不可用,但在训练期间可能很有用。以国家为基础的批评已经成为普遍的经验选择,尽管其理论依据或分析有限。本文证明了基于状态的批评者可以在策略梯度估计中引入偏差,这可能破坏算法的渐近保证。其还表明,即使基于状态的批评者没有引入任何偏差,它们仍然可以导致更大的梯度方差,与通常的直觉相反。最后,通过在广泛的共同基准上比较不同形式的集中批评来展示理论在实践中的效果,并详细说明各种环境属性如何与不同类型批评的有效性相关。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢