

论文标题:
Efficient Large Scale Language Modeling with Mixtures of Experts
代码:
https://github.com/pytorch/fairseq/tree/main/examples/moe_lm
摘要:
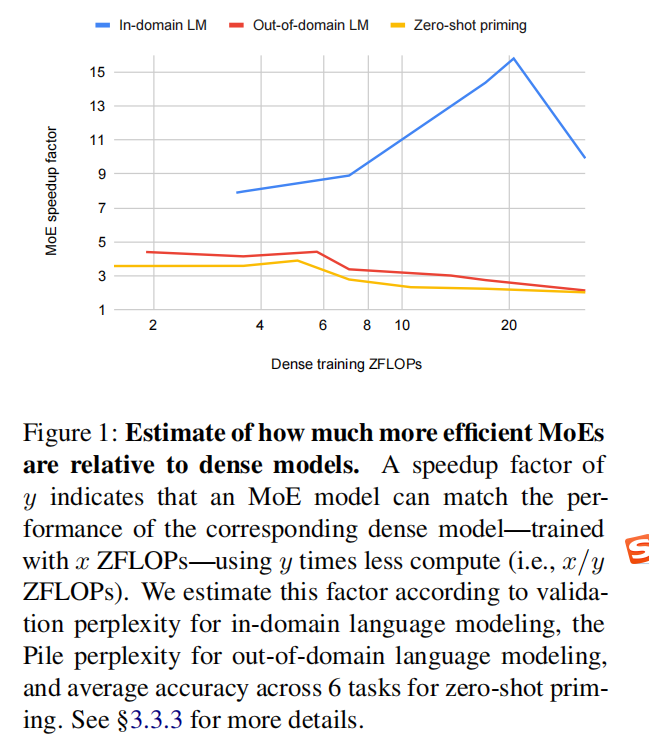
大型语言模型 (LM)通过增加训练和推理过程中使用的参数数量和计算量实现了卓越的准确性和泛化能力, 但是昂贵的计算资源需求的增长,对很多研究机构来说是无法承受的。同时,考虑到训练和部署此类大模型所需要的环境成本,从而激发人们研究更有效的模型设计。混合专家层 (Mixture of Experts layers, MoEs) 可通过有条件的计算有效地扩展语言模型。本文提出了一项详细的实证研究,研究了在各种设置中自回归 MoE 语言模型与密集模型相比规模如何,设置包括:域内(in-)和域外(out-of-domain)语言建模、零样本(zero-)和少样本(few-shot)启动以及完全微调(fine-tuning)。在没有微调的情况下,我们发现 MoEs 实际上具有更高的计算效率。 在更适度的训练预算下,MoEs 使用少约4倍的计算量来匹配密集模型的性能。 这种差距在规模上缩小,并且我们的最大的MoE模型(1.1T参数)始终优于计算等效(compute-equivalent)的密集模型(6.7B 参数)。 总体而言,这种性能差距在不同任务和领域之间有很大差异,这表明 MoE 和密集模型的泛化方式不同,值得未来研究。
贡献:
- 对大规模零样本和少样本学习的稀疏模型进行了全面研究;
- 证明了即使规模稀疏的 MoE模型也可以在零样本和少样本学习模型训练和推理的小部分计算中产生具有竞争力的性能;
- 观察到密集和稀疏模型在规模上泛化的一些差异,表明这两种的互补行为未来可能是一个有趣的研究方向。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢