
2017年,Google的一篇 Attention Is All You Need 为我们带来了Transformer,其在NLP领域的重大成功展示了它对时序数据的强大建模能力,自然有人想要把Transformer应用到时序数据预测上。在Transformer的基础上构建时序预测能力可以突破以往的诸多限制,最明显的一个增益点是,Transformer for TS可以基于Multi-head Attention结构具备同时建模长期和短期时序特征的能力。
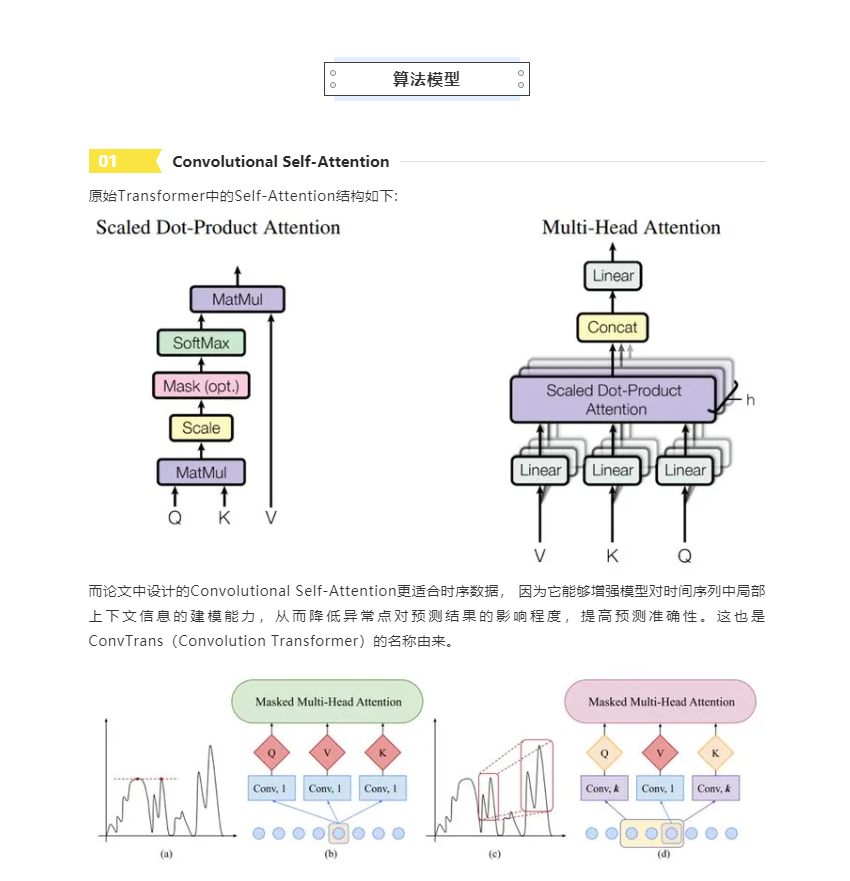
本文将要介绍的一个充分利用了Transformer的优势,并在Transformer的基础上改进了Attention的计算方式以适应时序数据,同时提出了一种解决Transformer拓展性差问题的算法:ConvTrans。论文来源于NeurIPS 2019的一篇文章,作者给出了基于PyTorch的具体实现。
论文来源:NeurIPS 2019
论文地址:https://arxiv.org/abs/1907.00235
论文源码:https://github.com/mlpotter/Transformer_Time_Series
一般来说,谈及DL领域时序预测,首先大家会想到RNN类的模型,但RNN在网络加深时存在梯度消失和梯度爆炸问题。即使是后续的LSTM,在捕捉长期依赖上依然力不从心。再后面有了Amazon提出的DeepAR,是一种针对大量相关时间序列统一建模的预测算法,该算法使用递归神经网络 (RNN) 结合自回归(AR) 来预测标量时间序列,在大量时间序列上训练自回归递归网络模型,并通过预测目标在序列每个时间步上取值的概率分布来完成预测任务。
ConvTrans
ConvTrans, 其实它与DeepAR有很多相似的地方,比如它也是一个自回归的概率预测模型,对于下一步预测采用分位数p10(分位数就是以概率将一批数据进行分割,比如 p10=a 代表一批数据中小于a的数占总数的10%)、 p50等;再比如ConvTrans也支持协变量预测,可以接受输入比如气温、事件、个体标识等等其他相关变量来辅助预测。
不同的是ConvTrans具备Transformer架构独有的优势,大致为以下四点:
-
支持并行,训练得更快。基于RNN的模型中每一个隐状态都依赖于它前一步的隐状态,因此必须从前向后必须逐个计算,每一次都只能前进一步。而Transformer没有这样的约束,输入的序列被并行处理,由此带来更快的训练速度。
-
更强的长期依赖建模能力,在长序列上效果更好。在前面提到过,基于RNN的方法面对长序列时无法完全消除梯度消失和梯度爆炸的问题,而Transformer架构则可以解决这个问题
-
Transformer可以同时建模长期依赖和短期依赖。Multi-head Attention中不同的head可以关注不同的模式。
-
Transformer的AttentionScore可以提供一定的可解释性。通过可视化AttentionScore可以看到当前预测对历史值注意力的分布。
当然Transformer for TS的架构也有相应的缺点:
-
是基于序列的编解码结构(seq2seq),编码器和解码器均采用基于自注意力机制的网络,所以计算空间复杂度大,需要处理序列的编解码。
-
原始Transformer的自注意力计算方法对局部信息不敏感,使得模型易受异常点影响,带来了潜在的优化问题。
而2019NeurIPS的论文针对这些缺点做了相应的2点改进:
-
Convolutional Self-Attention :针对时序数据预测任务的特点,增强对局部上下文信息的关注,使预测更精准 。
-
LogSparse :解决了Attention计算空间复杂度太高的问题,使模型能处理更长的时间序列数据。
论文作者对其模型进行完整的开源,代码包括 DataProcessor,TransformerTimeseries,Train与Prediction。采用pytorch框架实现,没有使用系数策略。具体参见如下地址:
https://github.com/mlpotter/Transformer_Time_Series/blob/master/
而对于Log Parse策略的实现,参见如下代码:
https://github.com/ghsama/ConvTransformerTimeSeries
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢