
2021年12月14日,哈工大讯飞联合实验室(HFL)以总分72.8获得多模态阅读理解评测VCR冠军。VCR评测(Visual Commonsense Reasoning)由华盛顿大学和AI2联合举办,旨在全面考察模型的多模态推理和理解能力。VCR评测举办以来吸引了众多知名高校和研究机构参加,其中包括快手、华盛顿大学、AI2、百度、腾讯微视、加利福尼亚大学伯克利分校(UC Berkeley)、微软、卡内基梅隆大学(CMU)、Facebook、Google等。
VCR评测从以下三个指标对机器进行评测:
-
Q2A:根据图像&问题选出答案
-
QA2R:根据图像&问题&答案选出推理论据
-
Q2AR(综合指标):根据图像&问题选出答案和推理论据
哈工大讯飞联合实验室提出的VL-RoBERTa多模态预训练模型以总成绩(Q2AR)72.8分位居VCR评测榜首,在Q2A及Q2AR指标上显著超越了榜单的第二名的成绩。
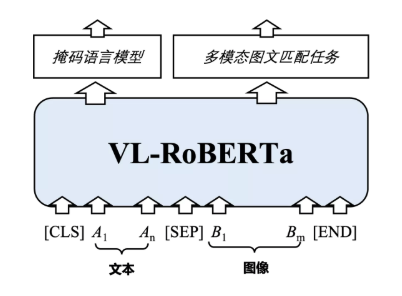
本次夺冠得益于团队自主研发的多模态预训练模型VL-RoBERTa。VL-RoBERTa在文本预训练模型RoBERTa的基础上加入了多模态处理模块,通过利用大规模文本数据以及多模态数据进行预训练,减少了对多模态数据的依赖,同时学习文本端的掩码语言模型(MLM)以及多模态图文匹配任务。同时,VL-RoBERTa创新地提出了一种增强式图文混合预训练机制(Enhanced Visual-Text Pre-training),构建重要图像目标与文本实体相对齐的预训练方法,使得模型能够精准地学习图像目标与文本实体之间的复杂语义关系,提升VCR任务的理解效果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢