
当下预训练模型的量化为了保证性能,大多采用量化感知训练(Quantization-aware Training, QAT)。而模型后量化(Post-training Quantization, PTQ)作为另一类常用量化方法,在预训练大模型领域却鲜有探索。诺亚方舟实验室的研究者从以下四个方面对 QAT 与 PTQ 进行了详细对比:
-
训练时间:QAT 由于模拟量化算子等操作,训练耗时远远超出全精度训练(FP),而 PTQ 仅仅需要几十分钟,大大缩短量化流程;
-
显存开销:QAT 显存消耗大于全精度训练(FP),使得在显存有限的设备上难以进行量化训练。而 PTQ 通过逐层回归训练,无需载入整个模型到显存中,从而减小显存开销;
-
数据依赖:QAT 需要获取整个训练数据集,而 PTQ 只需要随机采样少量校准数据,通常 1K~4K 张 / 条图像或者标注即可;
-
性能:鉴于 QAT 在整个训练集上充分训练,其性能在不同的量化 bit 上均领先 PTQ。因此性能是 PTQ 的主要瓶颈。
基于以上观测,研究者提出了针对视觉和 NLP 任务的 PTQ 方法,在保持其训练时间、显存开销、数据依赖上优势的同时,大大改善其性能,使其逼近量化感知训练的精度。具体而言,仅使用 1% 的训练数据和 1/150 的训练时间,即可达到 SOTA 量化方法的精度。
论文 1
论文标题:Post-Training Quantization for Vision Transformer
论文链接:https://arxiv.org/pdf/2106.14156.pdf
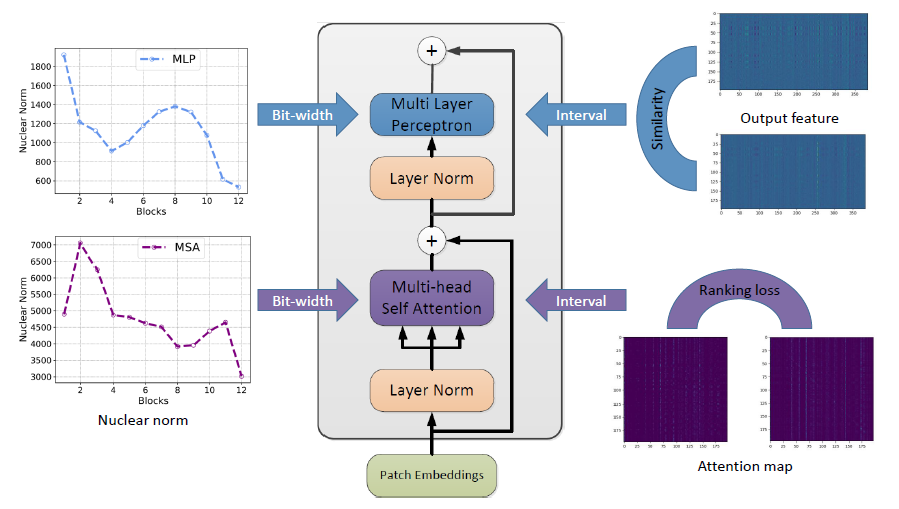
图 视觉 Transformer 后训练量化算法框架
论文 2
论文标题:Towards Efficient Post-training Quantization of Pre-trained Language Models
论文链接:https://arxiv.org/pdf/2109.15082.pdf
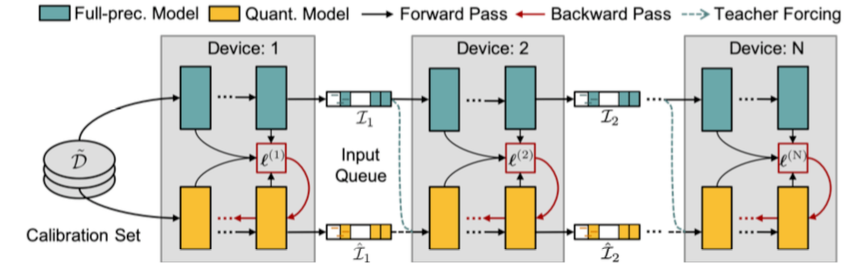 图 并行蒸馏下的模型后量化总体框架
图 并行蒸馏下的模型后量化总体框架
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢