
【论文链接】https://arxiv.org/pdf/2007.04973v4.pdf
学习源代码的上下文表征的一般思路是通过从上下文中重构掩盖符来进行,这些表征最好能捕捉到程序功能,然而这种方法对源代码形式很敏感。对此本文提出了ContraCode,一个对比学习的预训练任务,学习代码功能,而不是形式。ContraCode预训练一个神经网络,以便在许多非等价的干扰因素中识别功能相似的程序变体。本文使用一个自动的编译器作为数据增强的形式,可扩展地生成这些变体。对比性预训练将JavaScript总结和TypeScript类型推断的准确性提高了2%到13%。本文还提出了一个新的零样本的JavaScript代码克隆检测数据集,显示ContraCode既更强大又有语义意义。在这一数据集上,本文在对抗性设置中比RoBERTa的表现高出39%的AUROC,在自然代码上的表现则高达5%。
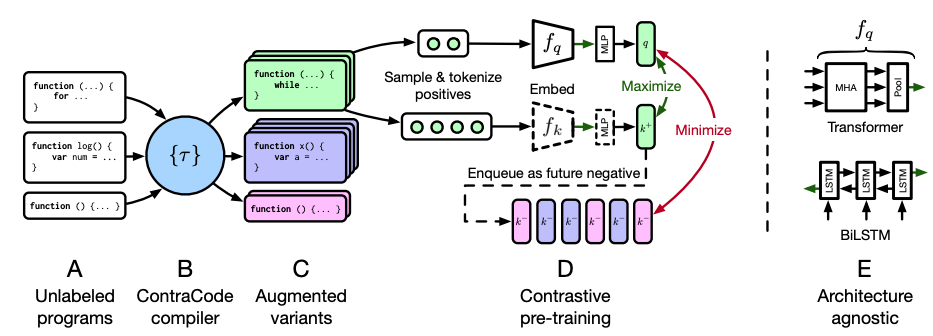
ContraCode进行预训练并将其迁移到下游任务中。A-C. 未标记的程序被转化为增强的变体。D. 本文通过最大限度地提高正面程序对(同一程序的变体)的投影嵌入的相似性来预训练,并最大限度地提高与缓存的负面程序队列的相似性。E. ContraCode支持任何能产生全局程序嵌入的架构,如Transformers和LSTMs,然后在较小的标记数据集上进行微调。

上图由RoBERTa和ContraCode学习的JavaScript方法表示的UMAP可视化。具有相同功能的程序共享颜色和编号。RoBERTa的嵌入通常不按功能分组,这表明它对实现细节很敏感。例如,许多不同的程序重叠,重命名程序19的变量大大改变了嵌入。相反,程序19的变体在ContraCode的嵌入空间中聚集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢