
论文连接:https://arxiv.org/pdf/2103.00020.pdf
github:https://github.com/openai/CLIP
最近CLIP比较火,身边人提到的也比较多,自己也开始尝试这篇论文,在这里做下记录。
数据:
这里首先想说下数据,CLIP 能够成功,并且很难自己复现的一个重要原因就是CLIP用了大量的训练数据以及训练资源,真的可以说是大力出奇迹。CLIP用了400million的image-text pair对进行训练,对于image backbone,CLIP尝试了两种结构,DN50x64 和 vit-L,分别用了592 个 V100 + 18天 的时间 和 256 个 V100 + 12天 的时间,一般人就直接劝退了。我们在用的时候也要先load其开源出来的已经训练好的模型才能work,自己无论是训练数据还是训练资源都不足以支撑clip的从头训练。
算法原理:
CLIP的基本算法原理相对比较简单,为了对image和text建立联系,首先分别对image和text进行特征提取,image特征提取的backbone可以是resnet系列模型也可以是VIT系列模型,text特征提取目前一般采用bert模型,特征提取之后,由于做了normalize,直接相乘来计算余弦距离,同一pair对的结果趋近于1,不同pair对的结果趋近于0,因为就可以采用对比损失loss(info-nce-loss),熟悉这个loss的同学应该都清楚,这种计算loss方式效果与batch size有很大关系,一般需要比较大的batch size才能有效果。
模型示意图:
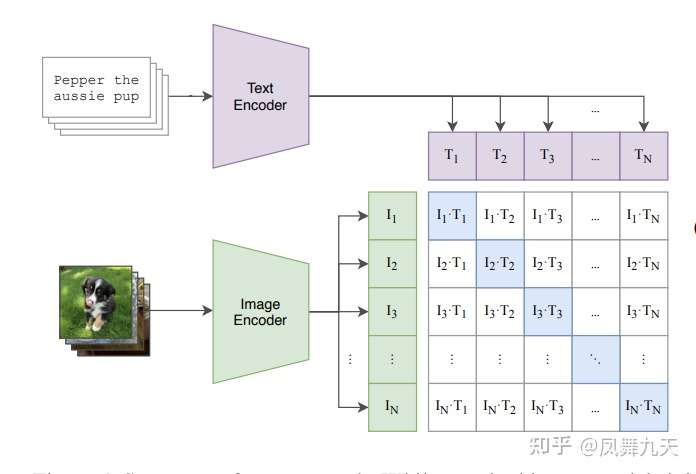
伪代码:

个人理解:
感觉CLIP也是一种多模态pretrain 方式,并且能够为文本和图像在特征域进行对齐,无论是在跨模态检索,还是在多模态 pretrain 方面,都有其用武之地。
应用:
图像分类:
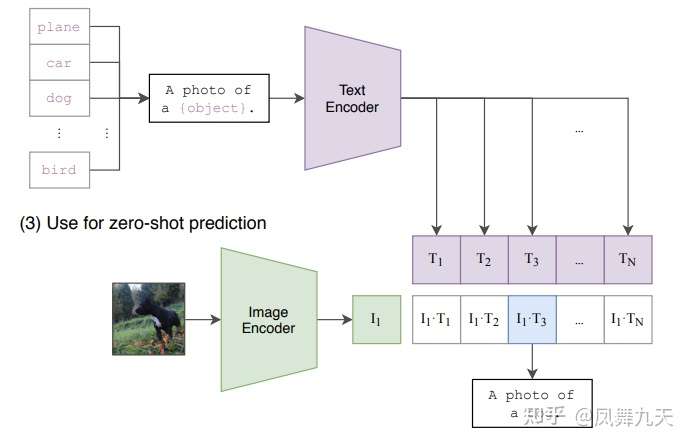
利用clip进行图像分类有两种方式,一种是直接利用zero-shot 方式进行预测,如下图所示,将text假设为 a photo of [object], 分别对image 和 text进行特征提取以及余弦距离,当object为目标类别时,相似度最高,即为预测结果,通过实验惊奇的发现,直接利用zero-shot 的方式进行预测能够达到76.2% 的acc,而且泛化性更好;还有一种方式就是再重新finetune,同样也是对类别设计几种不同的文本,这样效果能够达到sota的水平!
跨模态检索:
个人感觉CLIP提供了一种跨模态检索的方式,比如以文字搜图,其实这还是比较重要的应用。
总结
CLIP看起来简单,自己在实际用的时候发现效果也很好,美中不足就是太消耗训练资源,个燃感觉可以用类似moco的方式来减少对batch size的依赖。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢