
作者:Shen Yan, Xuehan Xiong, Anurag Arnab,等
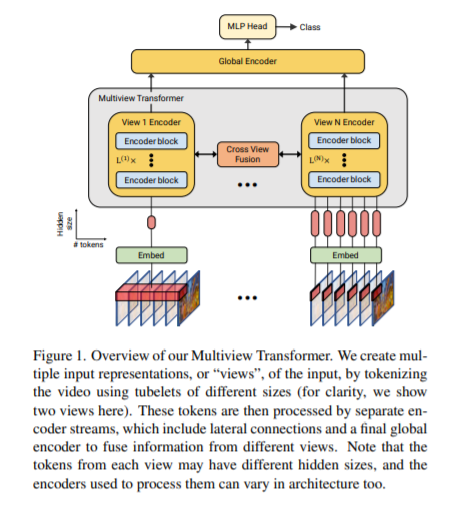
简介:本文研究基于transformer的视频理解方法。视频理解需要以多种时空分辨率进行推理——从短的细粒度运动到发生在较长时间内的事件。尽管 Transformer 架构最近取得了最新进展,但它们并未明确建模不同的时空分辨率。为此,作者提出了用于视频识别 (MTV) 的多视图transformer模型。作者的模型由单独的编码器组成,以表示输入视频的不同视图,并通过横向连接来融合跨视图的信息。作者对该模型进行了全面彻底的消融研究,并表明 MTV 在一系列模型大小的准确性和计算成本方面始终比单视图的对标表现更好。此外,作者在五个标准数据集上取得了最先进的结果,并通过大规模预训练进一步改进。作者将发布代码和预训练的检查点。
论文下载:https://arxiv.org/pdf/2201.04288.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢