
为了实现虚拟数字人的多域化渗透,让更多 AI 数字人的场景落地,FACEGOOD 决定将语音驱动口型的算法技术正式开源,这是 AI 虚拟数字人的核心算法,技术开源后将大程度降低 AI 数字人的开发门槛。
项目地址:
https://github.com/FACEGOOD/Audio2Face
该技术可以将语音实时转换成表情 blendshape 动画。FACEGOOD 对输入和输出数据做了相应的调整,声音数据对应的标签不再是模型动画的点云数据而是模型动画的 blendshape 权重。最终的使用流程如下图 1 所示:
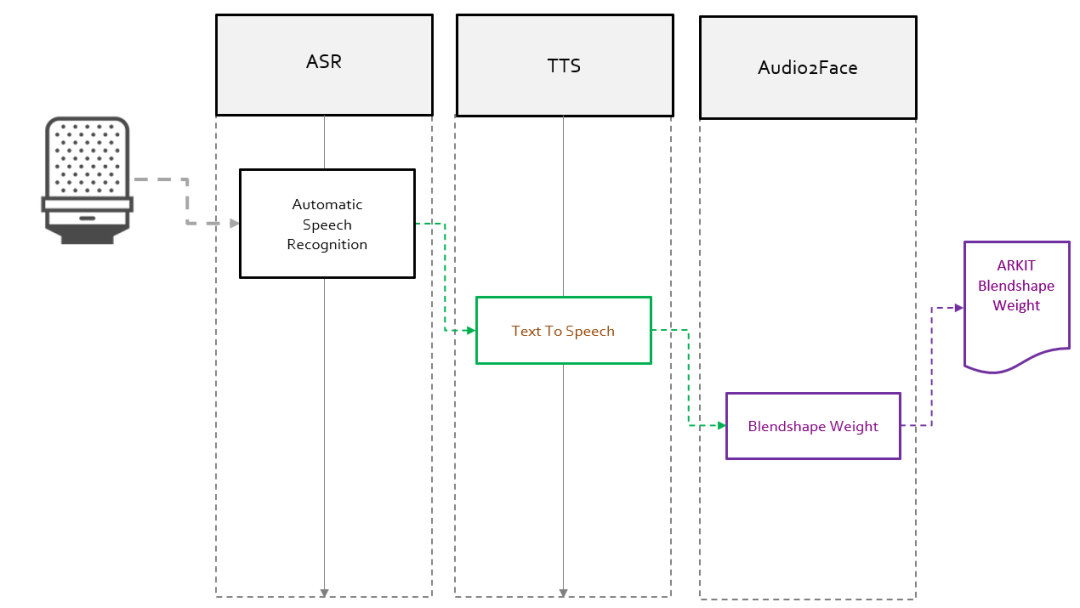
在上面的流程中,FACEGOOD 主要完成 Audio2Face 部分,ASR、TTS 由思必驰智能机器人完成。如果你想用自己的声音,或第三方的,ASR、TTS 可以自行进行替换。
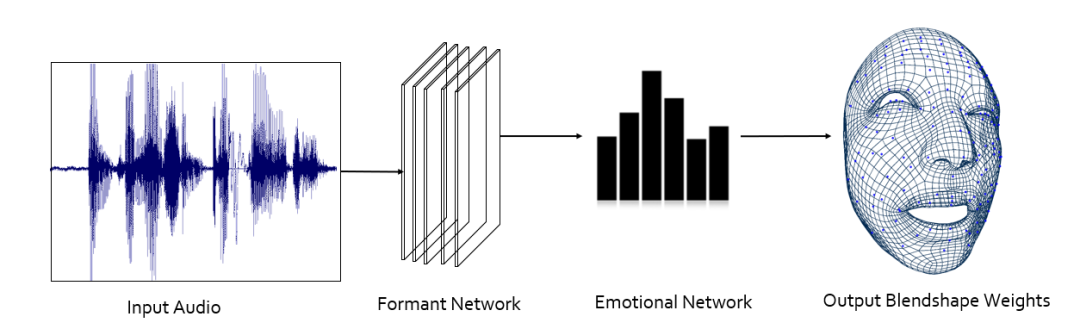
FACEGOOD Audio2Face 这一步的框架是什么样呢?又如何制作自己的训练数据呢?如下图 2 所示:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢