
作者:Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, Cordelia Schmid
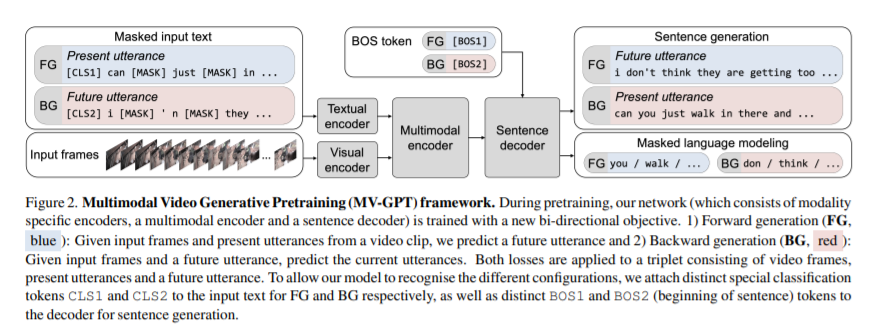
简介:本文创意地把“视频流中未来的话语”加入预训练、实现了新型高效的多模态视频生成模型。最近的视频和语言预训练框架往往缺乏生成句子的能力。作者提出了一种新的多模态视频生成预训练框架:MV-GPT,用于从未标记的视频中学习,可以有效地用于生成任务(例如多模态视频字幕)。与最近的视频语言预训练框架不同,作者的框架同时训练多模态视频编码器和句子解码器。为了克服未标记视频中缺少字幕的问题,作者利用视频中未来的话语作为额外的文本源,并提出了一个双向生成目标——作者在给定当前多模态上下文的情况下生成未来话语,并在给定未来观察的情况下生成当前话语。带着这个目标,作者提出的端到端训练编码器-解码器模型,以从原始像素生成字幕并直接转录语音。作者的模型在多模态视频字幕的四个基准上、以及其他视频理解任务(如 VideoQA、视频检索和动作分类)上实现了最先进性能。

论文下载:https://arxiv.org/pdf/2201.08264
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢