
论文标题:MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition

单位:FAIR(MViT、SlowFast等工作的作者团队), UC伯克利
论文:https://arxiv.org/abs/2201.08383
虽然今天的视频识别系统可以准确地解析snapshots 或者 short clips,但它们还不能在更长的时间范围内dots and reason。大多数现有的视频架构只能处理小于 5 秒的视频,而不会遇到计算或内存瓶颈。
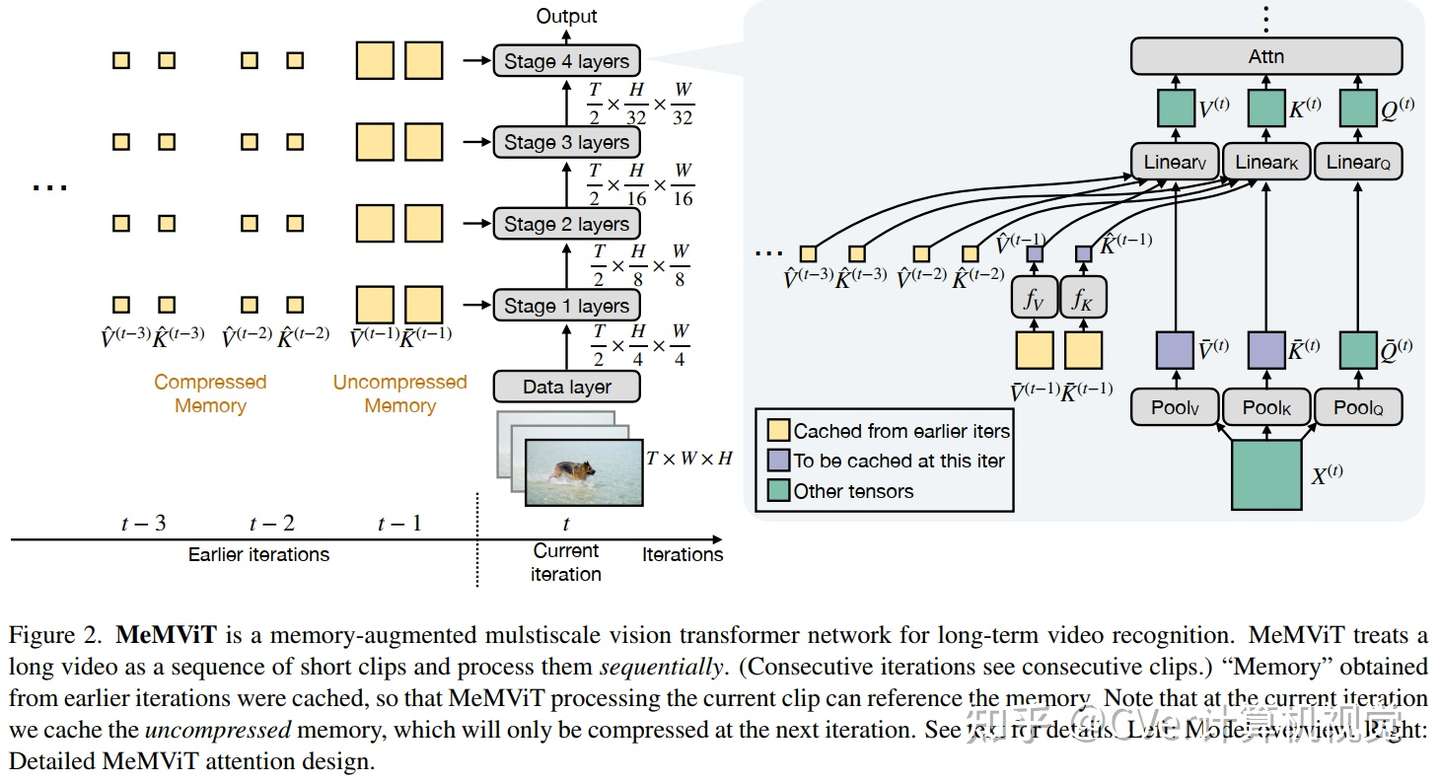
在本文中,我们提出了一种新的策略来克服这一挑战。我们提出以在线方式处理视频并在每次迭代时缓存“memory”,而不是像大多数现有方法那样尝试一次处理更多帧。通过记忆,模型可以参考先前的上下文进行长期建模,只需边际成本。
基于这个想法,我们构建了 MeMViT,一种记忆增强的多尺度视觉Transformer,它的时间支持比现有模型长 30 倍,计算量仅增加 4.5%;传统方法需要超过 3,000% 的计算才能做到这一点。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢