
【论文标题】LaMDA: Language Models for Dialog Applications
【作者团队】Romal Thoppilan, Quoc Le et al
【发表时间】2022/01/20
【机 构】斯坦福、谷歌
【论文链接】https://arxiv.org/pdf/2201.08239v1.pdf
本文提出了LaMDA,一个专门用于对话的基于Transformer的神经语言模型系列,它有多达137B的参数,并在1.56T字的公共对话数据和网络文本上进行了预训练。虽然单纯的模型扩展可以提高质量,但在安全性和事实基础上的改进较少。本文证明,用注释数据进行微调,并使模型能够检索外部知识,可以使安全和事实依据这两个关键挑战得到显著改善。其中第一个挑战,安全,涉及到确保模型的反应与一组人类价值相一致,例如防止有害的建议和不公平的偏见。本文使用一个基于人类价值观说明性集合的指标来量化安全性,并发现,使用一个用少量注释的数据微调的LaMDA分类器来过滤候选反应,很好地提高模型的安全性。第二个挑战是事实基础,包括使模型能够检索外部知识,如信息检索系统、语言翻译和网络。本文用一个基础性指标来量化事实性,发现该方法使模型能够理解已知外部来源,而不是仅仅听起来很合理的反应。最后,本文探讨了LaMDA在教育和内容推荐领域的使用,并分析了它们的帮助性和角色一致性。
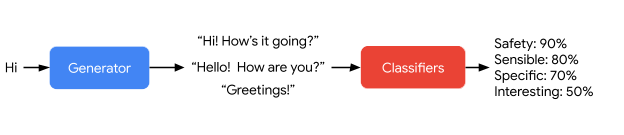
LaMDA 会生成一个响应候选,然后对其进行评分。
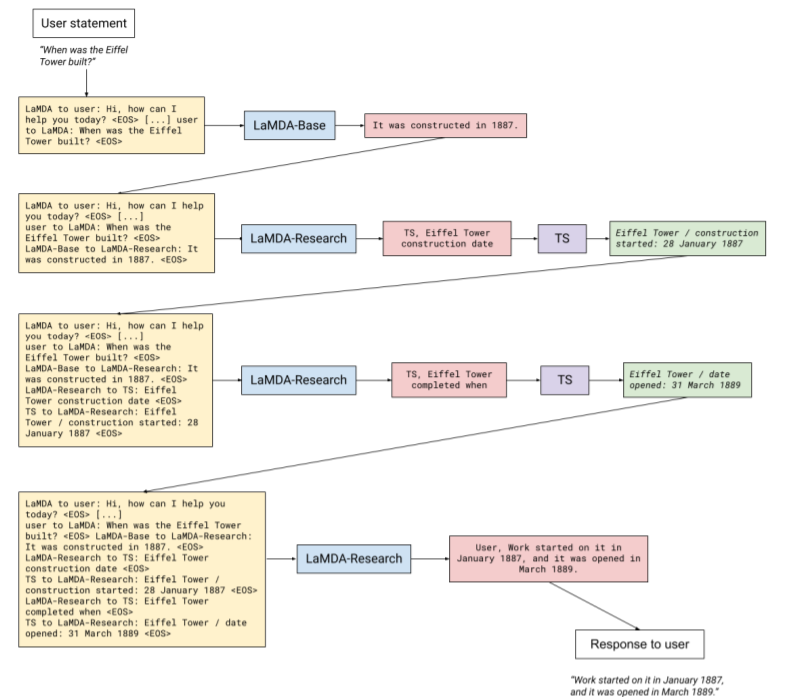
上图展示了LaMDA如何通过与外部信息检索系统的互动来处理真实。蓝色为模型,黄色为对模型的输入,红色为模型的输出,绿色为信息检索系统工具的输出。首先调用LaMDA-Base模型,然后再依次调用LaMDA-Research模型,在查询信息检索系统或回应用户之间的选择是由LaMDA-Research输出的第一个词决定的,它确定了下一个接收者。
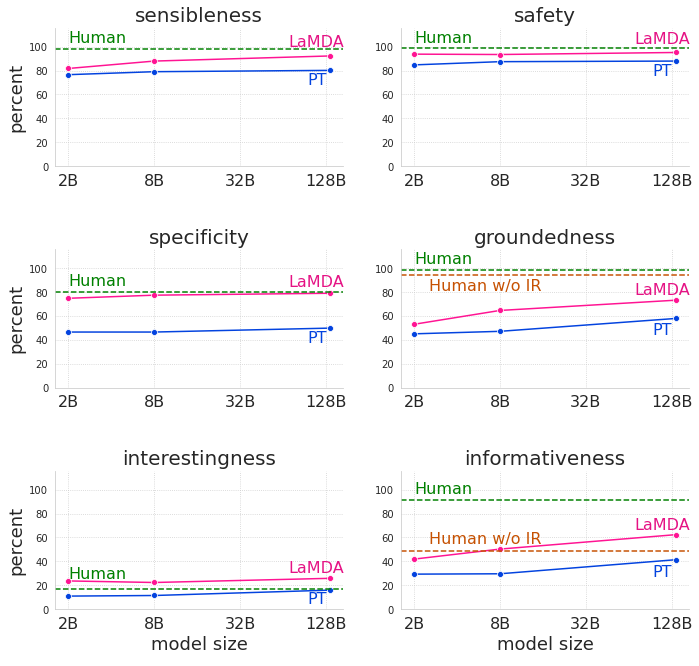
上图展示了模型的缩放和微调对六个基础指标的影响,具体展示了2B、8B和137B参数的预训练(PT)和微调(LaMDA)模型的结果,并与有机会使用信息检索工具('Human')和没有机会使用信息检索工具('Human w/o IR')的worker在敏感性、特异性、趣味性、安全性、扎实性和信息量方面。用于测量安全性和接地性的测试装置被设计得特别困难。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢