
作者:Haoyu Dong, Zhoujun Cheng, Xinyi He, 等
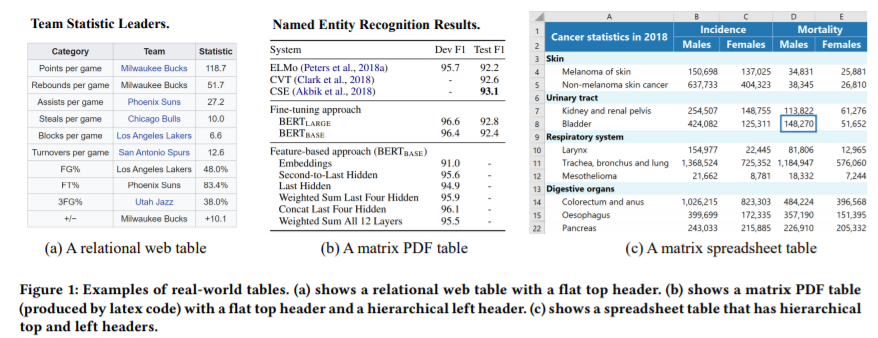
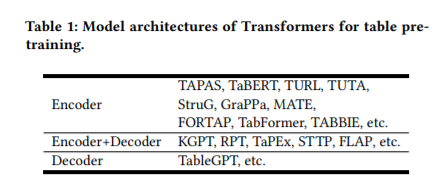
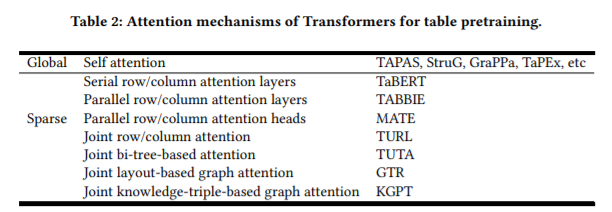
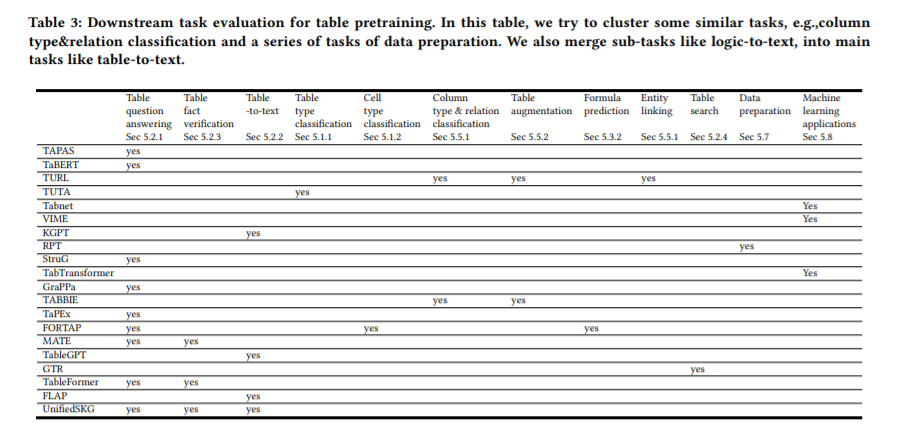
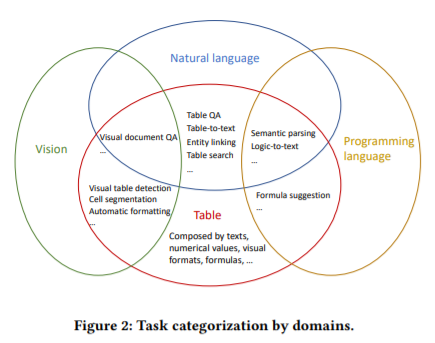
简介:本文是表格预训练的综述。由于人们可以方便地从网页、电子表格、PDF和各种其他文档类型中收集大量表格,继文本和图像在预训练领域的成功之后,业界提出了一系列表格预训练框架,并已经在表格问答、表格类型识别、列关系分类、表搜索、公式预测等任务中获取了SOTA效果。为了充分利用未标记表中的监督信号,诸如“去噪单元值”、“预测数值关系”和“隐式执行SQL”等各种预训练目标:已经被设计并评估。为了更好地利用结构化及半结构化表格的特点,业界探索了各种表格语言模型,尤其是经特别设计的attention机制。由于表格经常与自由文本出现并交互,因此表格预训练:通常采用“表格-文本”联合预训练的形式,而这已引起了多个领域的重大研究兴趣。本次综述,旨在全面回顾不同的表格模型设计、预训练目标、以及表格预训练的下游任务。本文还分享了作者对表格预训练现有挑战和未来机遇的想法和愿景。
论文下载:https://arxiv.org/pdf/2201.09745
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢