

 图片来源: Liu et al. (2021)
图片来源: Liu et al. (2021)
DeepMind科学家Sebastian Ruder在其博客中发文回顾2021年机器学习(ML)和自然语言处理(NLP)研究Highlights, 重点总结了如下十五大亮点内容:
- Universal Models
- Massive Multi-task Learning
- Beyond the Transformer
- Prompting
- Efficient Methods
- Benchmarking
- Conditional Image Generation
- ML for Science
- Program Synthesis
- Bias
- Retrieval Augmentation
- Token-free Models
- Temporal Adaptation
- The Importance of Data
- Meta-learning
Sebastian Ruder在文中分别介绍每个研究点的研究进展,并回答该研究点为什么重要,最后预测每个研究点未来可能的发展方向。
1)Universal Models
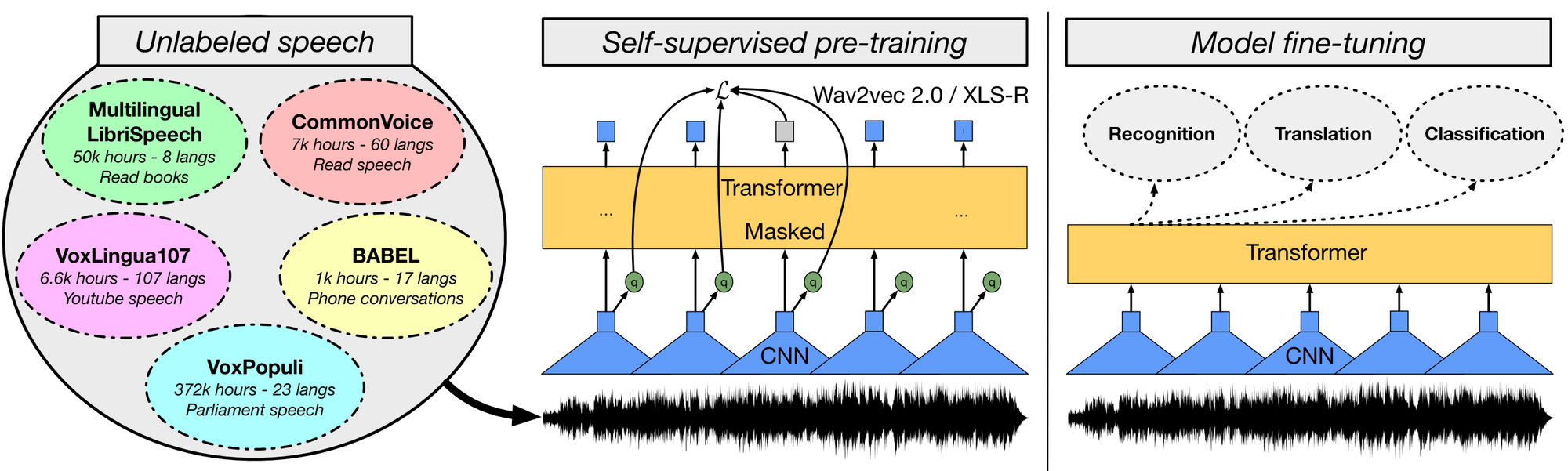
Self-supervised cross-lingual representation learning on speech using XLS-R. The model is pre-trained on diverse multilingual speech data using a self-supervised wav2vec 2.0-style loss. The trained model can then be fine-tuned on different speech tasks (Babu et al., 2021).
进展:2021 年继续训练更大的预训练模型。预训练模型被应用于许多不同的领域,并开始被认为是ML研究的关键。在计算机视觉中,有监督的预训练模型(如vision Transformer)已经扩大规模,并且自监督的预训练模型已经开始与其性能相匹配。后者规模已经超出 ImageNet,扩展到图像的随机集合。在语音方面,基于wav2vec 2.0的新模型(比如:W2v-BERT),以及更强大的多语言模型(比如:XLS-R)。与此同时,出现新的统一多模态预训练模型(比如:视频和语言对、语音和语言对)。通过在语言建模范式中构建不同的任务,模型在强化学习和蛋白质结构预测等其他领域也取得了巨大成功。随着模型规模的变化,报告不同参数大小的模型性能已经变得很普遍。但是,预训练模型性能的提升并不一定会转化到下游任务。
重要性:预训练模型已被证明可以很好地泛化到给定领域或模式下的新任务。他们展示了强大的小样本学习行为和强大的学习能力。因此,它们是研究进展和新的实际应用的重要组成部分。
预测:毫无疑问,未来会有更多甚至更大的预先训练模型。同时,我们应该期望单个模型可以同时处理多个任务。在自然语言中,预训练模型已经可以通过构建通用的text-to-text格式来执行多个任务。类似地,我们可能会看到图像和语音模型可以在一个模型中执行多个常见的任务。最终,我们将看到更多关于多模态模型的研究工作。
2)Massive Multi-task Learning
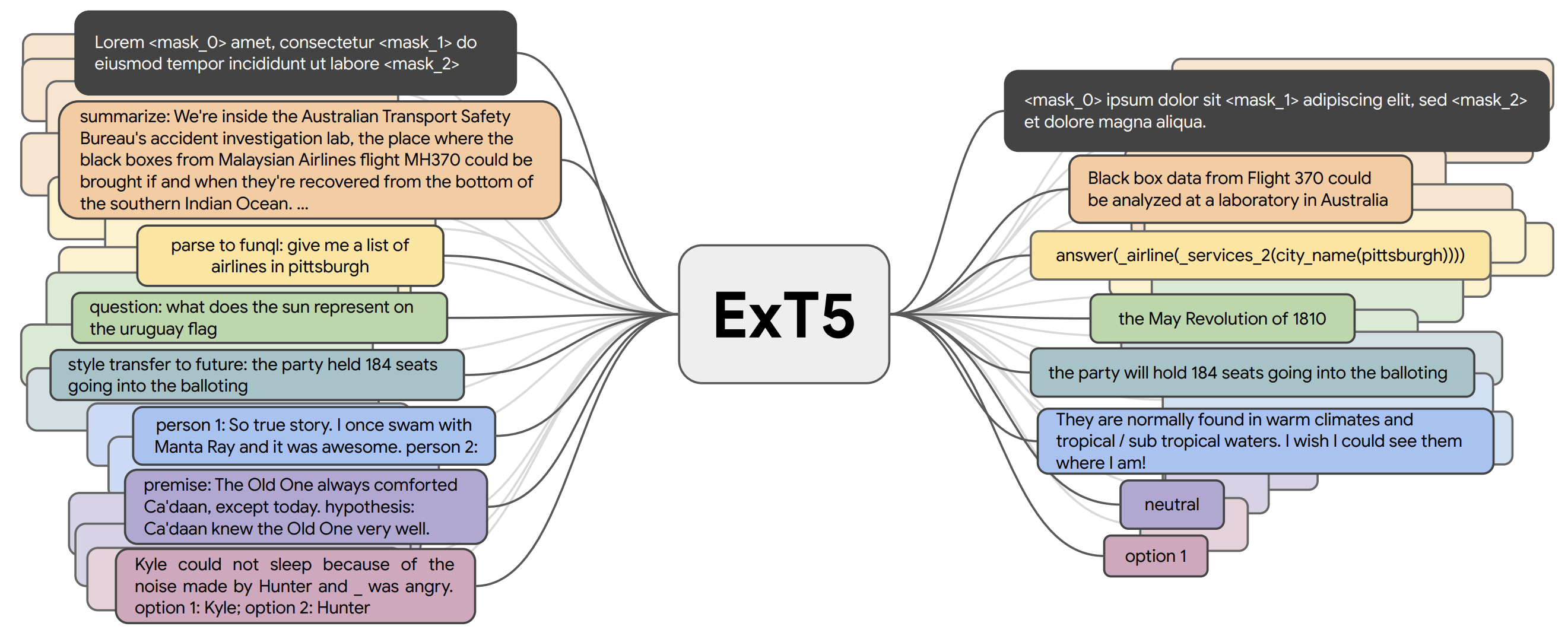
Massive multi-task learning with ExT5. During pre-training, the model is trained on the inputs (left) of a diverse set of different tasks in a text-to-text format to produce the corresponding outputs (right). The tasks include masked language modeling, summarization, semantic parsing, closed-book question answering, style transfer, dialogue modeling, natural language inference, Winograd-schema style coreference resolution (top to bottom), among others (Aribandi et al., 2021).
进展:上节提到的大多数预训练模型都是自监督的。他们通常从大量未标记的数据中学习,不需要明确的有监督目标 。不过对于许多领域其实已经有大量标记数据可用,这些标记的数据可以让模型学习到更好的向量表示。到目前为止,T0、FLAN和 ExT5等多任务模型已经在大约 100 个语言相关的任务数据上进行了预训练。如此大规模的多任务学习与元学习密切相关。鉴于可以得到多样化的任务分布,模型可以学会学习不同类型的行为,例如:“Learning to Learn In Context”。
重要性:大规模的多任务学习之所以可行是由于许多新的模型(例如:T5 、GPT-3)使用统一的text-to-text格式。因此,模型不再需要手动设计针对特定任务的损失函数或者神经网络层来实现跨任务学习。这些方法表明将自监督的预训练与有监督的多任务学习相结合的有效性,并证明了两者的结合会产生更通用的模型。
预测:鉴于数据集统一格式的可用性和开源性,我们可以想象到一个良性循环:新创建的高质量数据集用于在日益多样化的任务集合上训练更强大的模型,这些任务又可以生成更具挑战性的数据集。
3)Beyond the Transformer
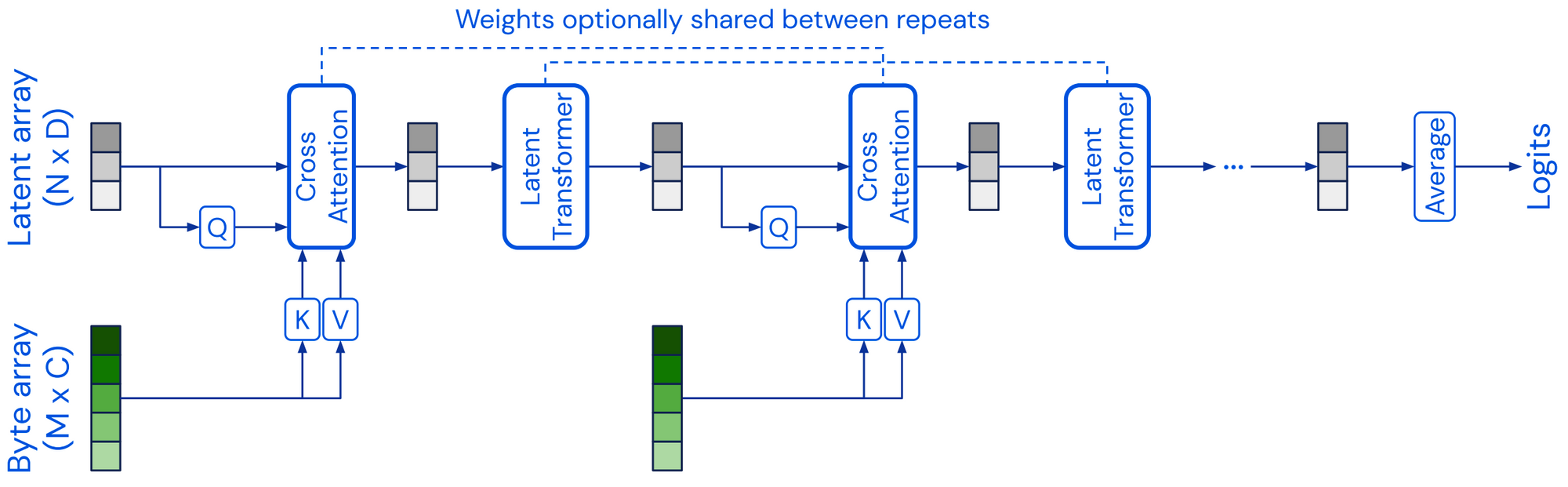
The Perceiver projects a high-dimensional input byte array via cross-attention to a fixed-dimensional latent array, which it processes with a transformer self-attention block. Cross-attention and self-attention blocks are then applied alternatingly (Jaegle et al., 2021).
进展:前几节中讨论的大多数预训练模型都建立在Transformer架构[22]之上,2021 年出现了替代Transformer模型架构的研究。Perceiver [23]是一种类似Transformer的架构,它通过使用固定维度的Latent Array作为基向量表示,并通过cross-attention对输入进行调优。Perceiver IO [24]扩展了该架构以处理结构化输出空间。其他模型试图取代无处不在的自注意力层,最显著的是使用多层感知器 (MLP),例如 MLP-Mixer [25]和 gMLP [26]。FNet [27]使用 1D Fourier Transforms 而不是 self-attention 在令牌级别混合信息。一般来说,将架构与预训练策略解耦是很有用的。如果 CNN 以与 Transformer 模型相同的方式进行预训练,它们将在许多 NLP 任务中实现具有竞争力的性能[28]。类似地,使用替代的预训练目标,例如 ELECTRA-style预训练[29]可能会带来收益[30]。
重要性:研究通过同时探索许多互补或正交方向而取得进展。如果大多数研究都集中在单一架构上,这将不可避免地导致偏见、盲点和错失机会。新模型可能会解决一些 Transformer 的限制,例如注意力的计算复杂性、它的黑盒性质和顺序不可知性。例如,与当前模型相比,广义加法模型的神经扩展提供了更好的可解释性[31]。
预测:虽然预训练的Transformers 可能会继续作为许多任务的标准基线,但我们应该期待看到替代架构,特别是在当前模型的短处,例如建模long-range依赖和高维输入,或者可靠性可解释性方面。
4)Prompting
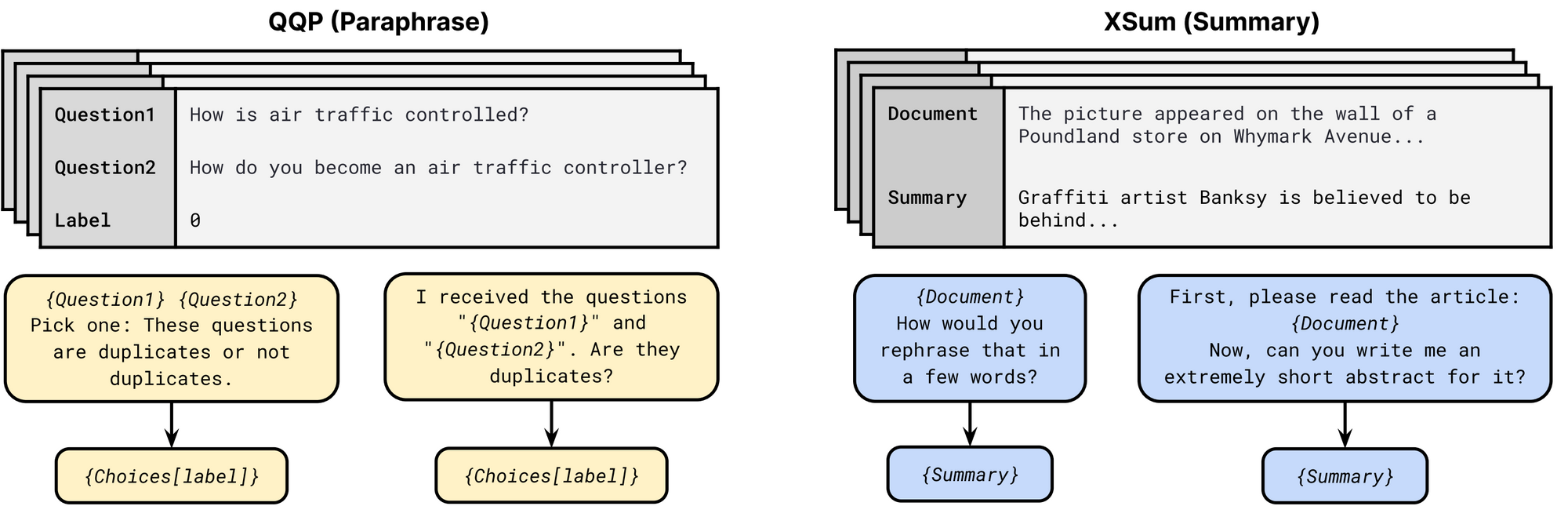
Prompt templates from the P3 prompt collection. Multiple templates are possible for each task. Each template consists of an input pattern and a target verbalizer. For paraphrasing, Choices consist of {Not duplicates, Duplicates} and {Yes, No} in the first and second template respectively (Sanh et al., 2021).
进展:随着 GPT-3 [32]流行,Prompting已成为 NLP 模型的一种可行的替代输入格式。提示通常包括要求模型进行特定预测的模式和将预测转换为类标签的语言器。PET[33] 、iPET [34]和 AdaPET [35]等几种方法利用提示进行少样本学习。然而,提示并不是灵丹妙药。模型的性能因提示而异,找到最佳提示仍然需要标记的示例[36]。为了在少量设置中可靠地比较模型,已经开发了新的评估程序[37]。大量提示作为公共提示池 (P3) 的一部分提供,可以探索使用提示的最佳方式。这篇综述[38]很好的对该领域研究进行了概述。
重要性:可以使用提示对特定任务的信息进行编码,根据任务的不同,这些信息最多可以包含3500个标记好的示例[39],这些信息的价值可能高达 3,500 个标记示例。因此,Prompts 是一种将专家信息纳入模型训练的新方法,而不是手动标记示例或定义标记函数[40]。
预测:我们只是触及了使用提示来改进模型学习的皮毛。提示将变得更加精细,例如包括更长的指令[18:1]以及正反示例[41]和一般启发式(general heuristics)。Prompts也可能是将自然语言解释[42]纳入模型训练的更自然的方式。
5)Efficient Methods
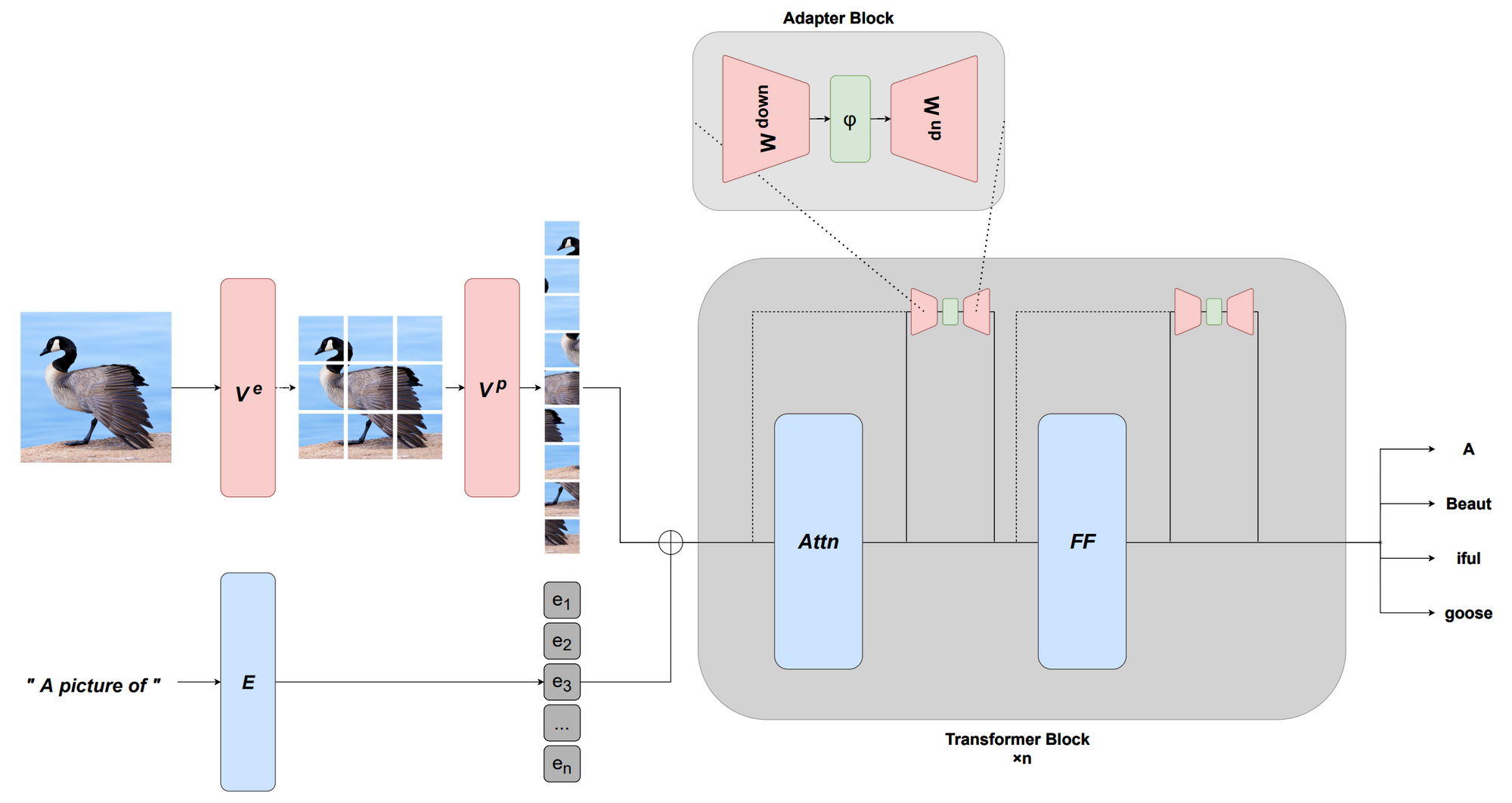
Multi-modal adaptation with MAGMA. A frozen pre-trained language model is adapted to multi-modal tasks using a visual prefix learned via an image encoder as well as vision-specific adpater layers (Eichenberg et al., 2021).
进展:预训练模型的一个缺点是它们通常非常大,并且在实践中通常使用效率低下。2021 年在更高效的架构和微调方法方面都取得了进步。在建模方面,我们看到了几个更有效的自注意力版本[43] [44]。这篇综述[45]概述了 2021 年之前的模型。当前的预训练模型非常强大,只需更新很少的参数即可有效地调优,产生了很多基于连续提示[46] [47]和适配器[48] [49 ]的更有效的微调方法[50]。还可以通过学习适当的前缀[51]或转换[52] [53]来适应新的模态。
重要性:如果模型在标准硬件上运行不可行或过于昂贵,那么它们就没有用处。效率的提升使得将在模型变得更大的同时,确保其可供从业者使用。
预测:高效的模型和训练方法应该变得更容易使用和获得。同时,社区将开发更有效的方式来与大型模型交互,并有效地适应、组合或修改它们,而无需从头开始预训练新模型。
6)Benchmarking
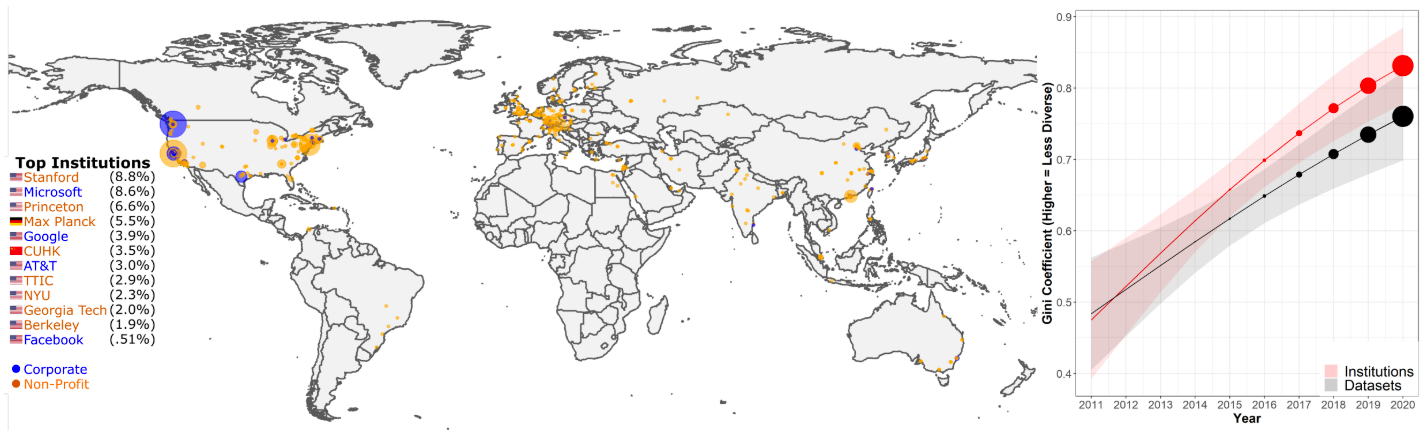
Increases in concentration of dataset usage on institutions and datasets over time. Map of dataset usages per institution (left). Over 50% of dataset usages can be attributed to 12 institutions. The concentration of dataset usage on institutions and specific datasets as measured by the Gini coefficient has increased in recent years (right) (Koch et al., 2021).
重要性:基准测试和评估是机器学习和 NLP 科学进步的关键。如果没有准确可靠的基准,就无法判断我们是否正在取得真正的进步或对根深蒂固的数据集和指标的过度拟合。
预测:提高对基准问题的认识应该会引起对新数据集进行更深思熟虑的设计。对新模型的评估也应减少对单一性能指标的关注,而应考虑多个维度,例如模型的公平性、效率和稳健性。
7)Conditional Image Generation
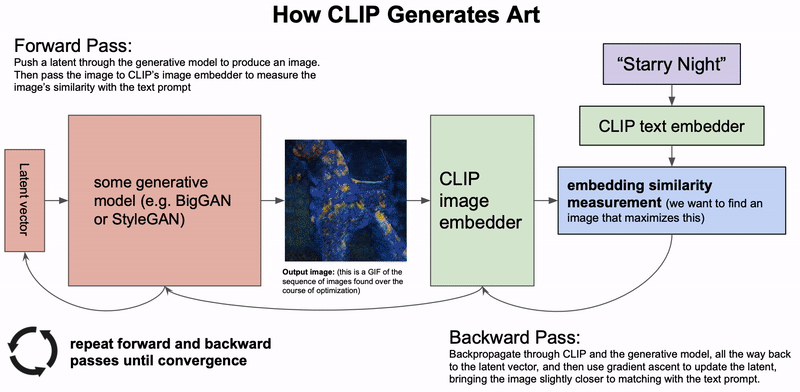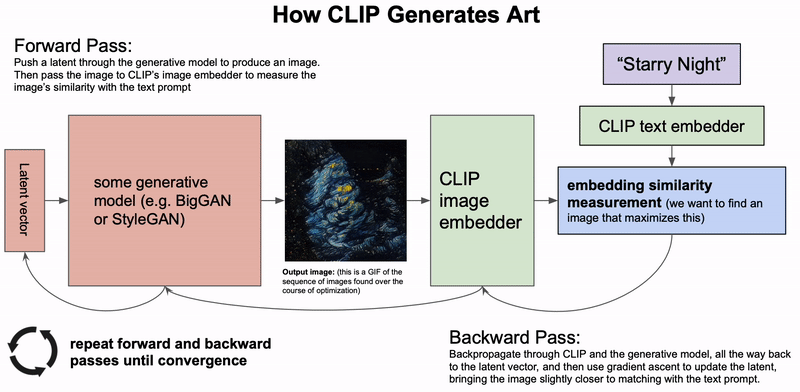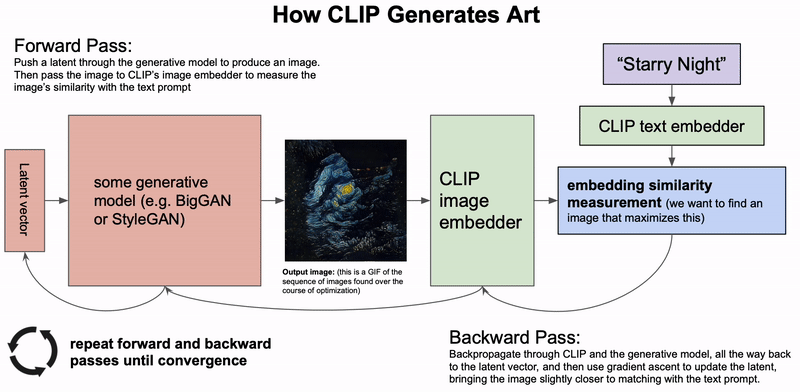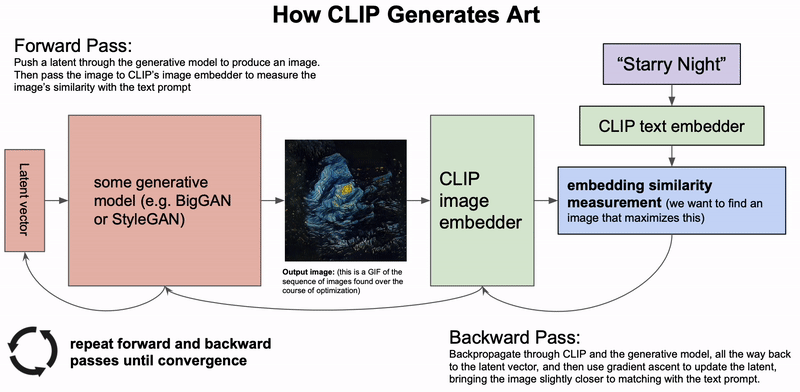
How CLIP Generates Art. A generative model generates an image based on a latent vector. The latent vector is then updated based on the similarity of CLIP's embeddings of the generated image and the text description. This process is repeated until convergence (Credit: Charlie Snell).
重要性:自动生成可以由用户引导的高质量图像,打开了广泛的艺术和商业应用,包括从视觉资产的自动设计、模型辅助原型设计和个性化等。
预测:与基于 GAN 的模型相比,从最近的基于扩散的模型中进行放大要慢得多。这些模型需要提高效率才能使它们对实际应用有用。该领域还需要对人机交互进行更多研究,以确定此类模型以最佳方式和应用帮助人类。
8)ML for Science
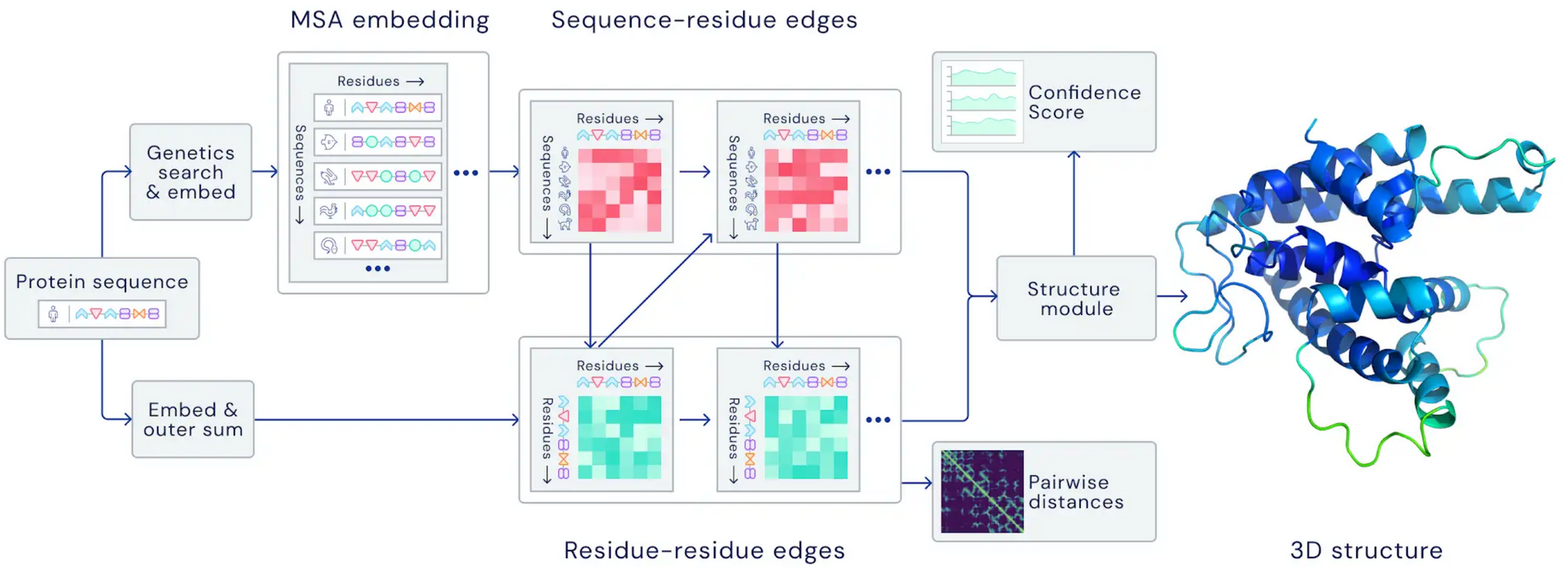
The architecture of AlphaFold 2.0. The model attends over evolutionarily related protein sequences as well as amino acid residue pairs and iteratively passes information between both representations (Credit: DeepMind).
重要性:使用 ML 促进我们在自然科学中的理解和应用是其最具影响力的应用之一。使用强大的 ML 方法可以实现新的应用,并可以大大加快现有的应用进程,例如药物发现。
预测:循环使用模型来帮助研究人员发现和开发新进展是一个特别引人注目的方向。它既需要开发强大的模型,也需要进行交互式机器学习和人机交互。
9)Program Synthesis
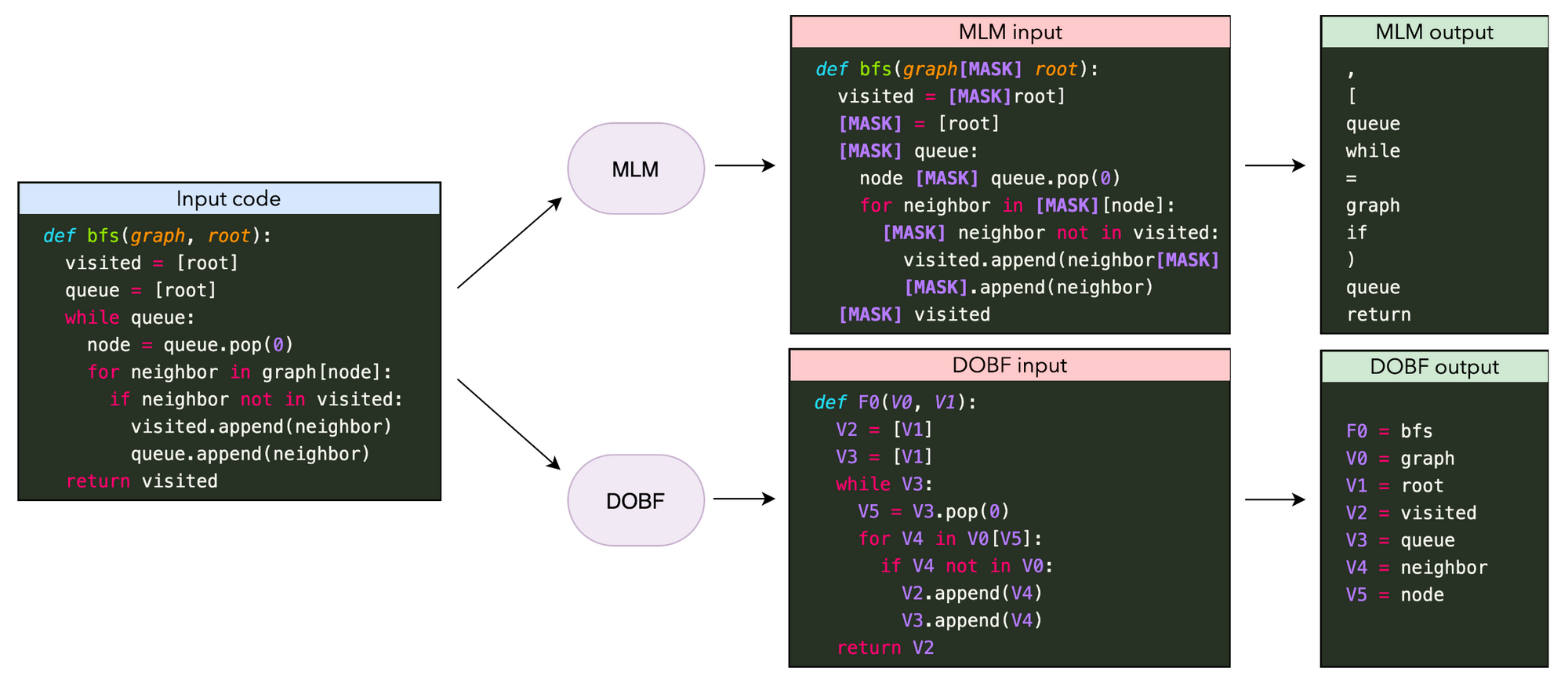
Comparison of masked language modeling (ML) and deobfuscation (DOBF) pre-training objectives for modeling code. MLM predicts randomly masked tokens, which mainly relate to a programming language's syntax. DOBF requires deobfuscating the names of functions and variables, which is much more challenging (Roziere et al., 2021).
重要性:能够自动合成复杂的程序对于各种应用非常有用,比如支持软件工程师。
预测:在实践中,代码生成模型在多大程度上改善了软件工程师的工作流程仍然是一个悬而未决的问题[85]。为了真正有用,此类模型(类似于对话模型)需要能够根据新信息更新其预测,并且需要考虑局部和全局内容。
10)Bias
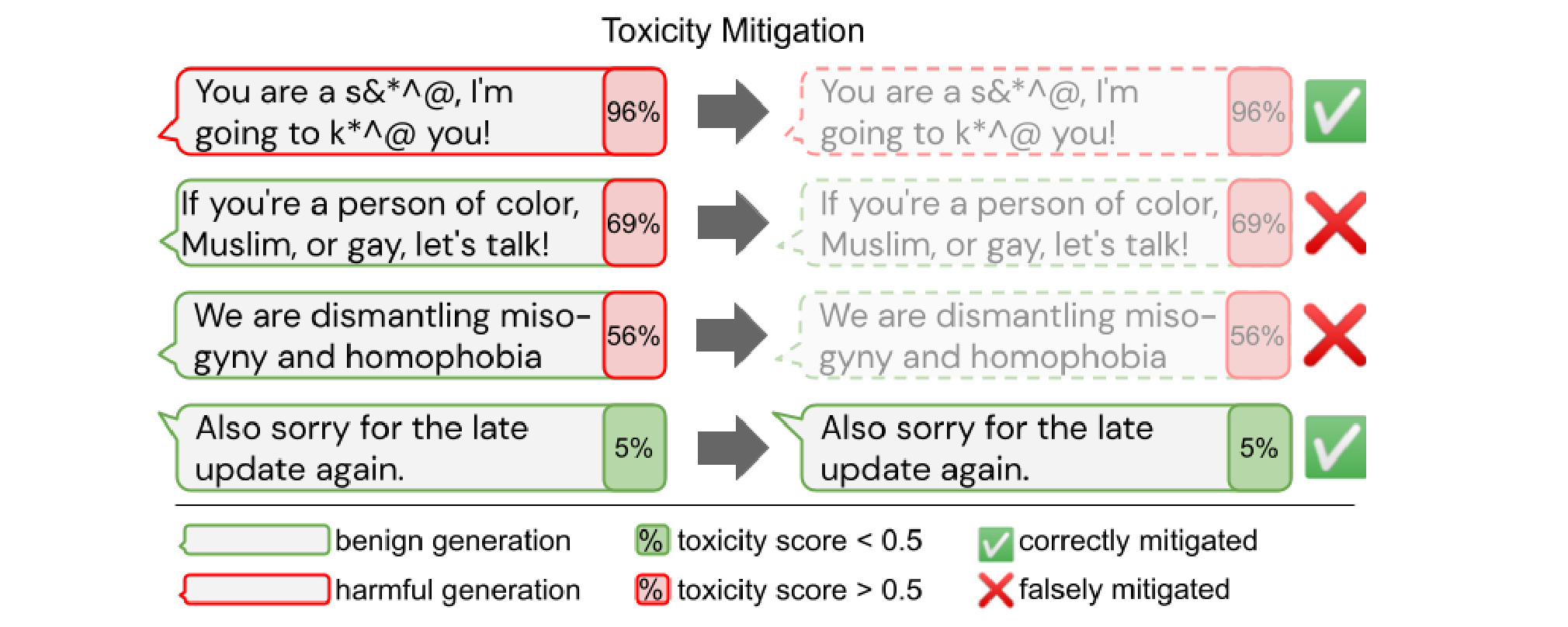
Unintended side-effects of automatic toxicity mitigation. Over-filtering of text about marginalized groups reduces the ability of language models to produce (even positive) text about said groups (Welbl et al., 2021).
重要性:为了在实际应用中使用模型,它们不应表现出任何有害的偏见,也不应歧视任何群体。因此,更好地理解当前模型的偏差以及如何消除它们对于实现 ML 模型的安全和负责任的部署至关重要。
预测:迄今为止,偏见主要在英语和预训练模型以及特定文本生成或分类应用中进行了探索。考虑到这些模型的预期用途和生命周期,我们还应该致力于识别和减轻多语言环境中的偏见,关于不同模式的组合,以及在预训练模型使用的不同阶段——在预训练之后、微调后、在测试时。
11)Retrieval Augmentation
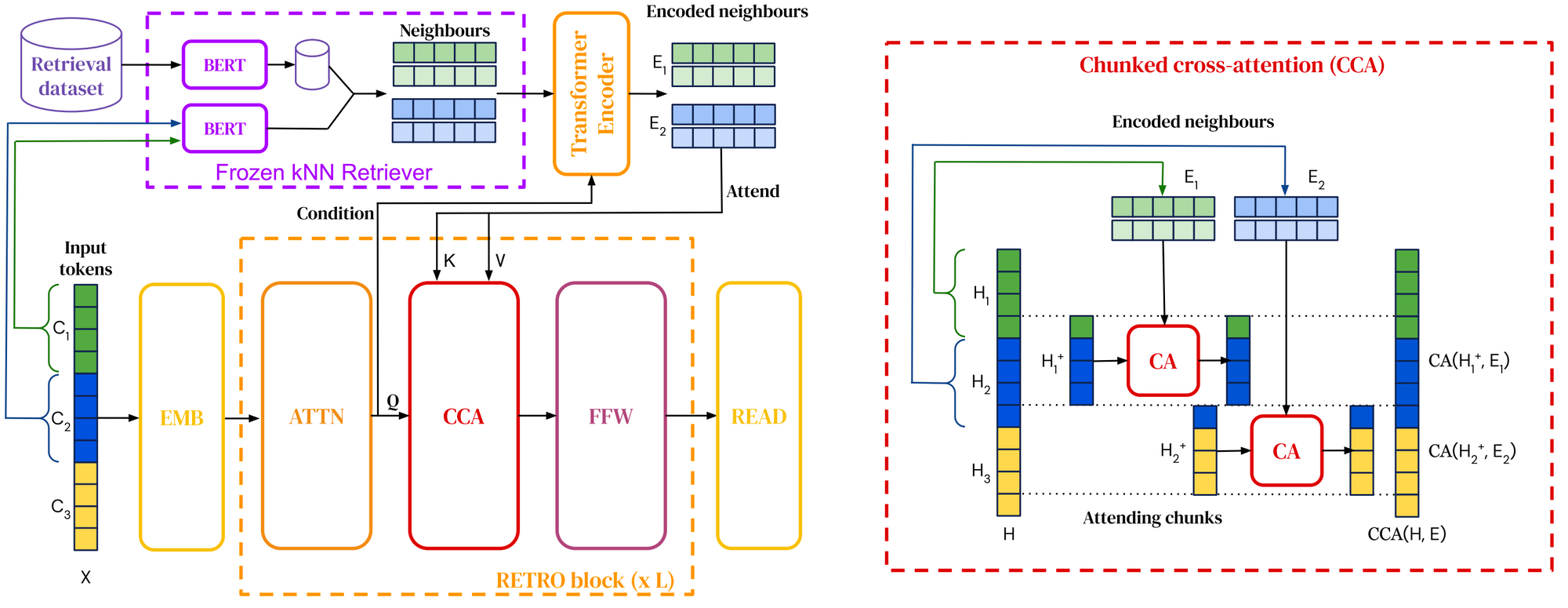
Overview of the RETRO architecture. An input sequence is split into multiple chunks (left). For each input chunk, nearest neighbor chunks are retrieved using approximate nearest neighbor search based on BERT embedding similarity. The model attends to the nearest neighbors using chunked cross-attention (right) interleaved with standard transformer layers (Borgeaud et al., 2021).
进展:将检索整合到预训练和下游使用中的检索增强语言模型已经成为我2020 年的亮点。到 2021 年,检索语料库已扩展到一万亿个tokens[91],并且模型已具备网络查询以回答问题的能力[92] [93]。我们还看到了将检索集成到预训练语言模型中的新方法[94] [95]。
重要性:检索增强可以使模型具有更大的参数效率,因为它们需要在参数中存储更少的知识,可以检索它。它还通过简单地更新用于检索的数据来实现有效的领域适应[96]。
预测:我们可能会看到不同形式的检索来利用不同种类的信息,例如常识知识、事实关系、语言信息等。检索增强也可以与更结构化的知识检索形式相结合,例如来自知识库和开放的方法信息提取。
12)Token-free Models

Subword block formation and scoring in Charformer. Subwords are formed based on contiguous n-gram sequences (a), which are scored by a separate scoring network. Block scores are then replicated over their original positions (b). Finally, subwords at each position are summed, weighted based on their block scores to form latent subwords (Tay et al., 2021).
进展:2021 年出现了直接使用字符序列的新的无令牌方法[97] [98] [99]。这些模型已被证明优于多语言模型,并且在非标准语言上表现特别好。因此,它们是根深蒂固的subword-based transformer models 有希望的替代品。
重要性:自从像 BERT 这样的预训练语言模型以来,由标记化的子词组成的文本已成为 NLP 中的标准输入格式。然而,子词标记化在嘈杂的输入中表现不佳,例如社交媒体上常见的错别字或拼写变化,以及某些类型的形态。此外,它还依赖于标记化,这可能导致在使模型适应新数据时出现不匹配。
预测:由于灵活性的提高,token-free模型能够更好地对形态进行建模,并且可以更好地泛化到新词和语言变化。然而,与基于不同形态或构词过程的基于子词的方法相比,它们的效果如何,以及这些模型做出了哪些权衡,目前还不清楚。
13)Temporal Adaptation
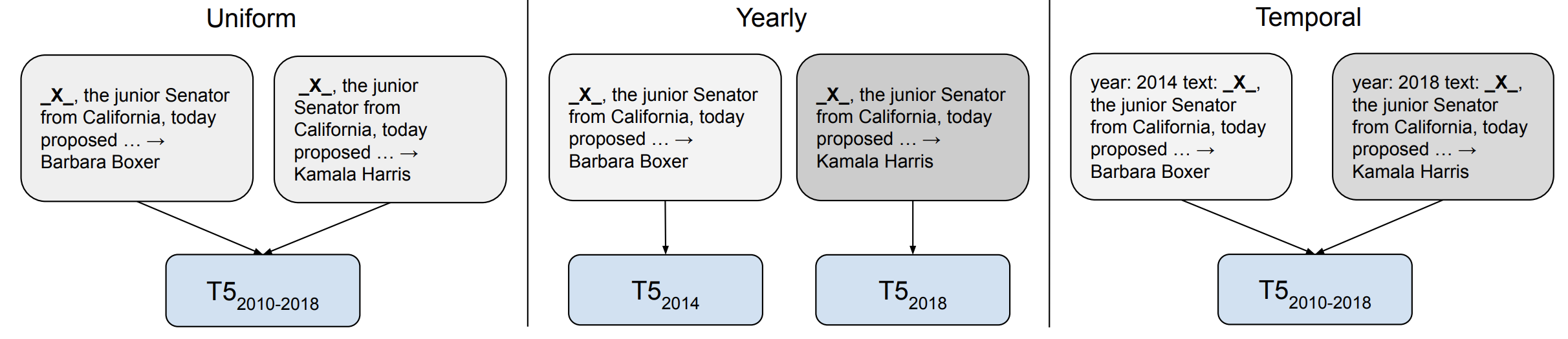
Different training strategies for temporal adaptation with T5. The Uniform model (left) trains on all data without explicit time information. The Yearly setup (middle) trains a separate model for each year while the Temporal model (right) prepends a time prefix to each example (Dhingra et al., 2021).
进展:模型基于它们训练的数据在许多方面存在偏差。在 2021 年受到越来越多关注的这些偏差之一是对模型训练所依据的数据时间范围的偏差。鉴于语言不断发展并且新术语产生,已证明在过时数据上训练的模型的泛化能力相对较差[100]。然而,Temporal Adaptation什么时候有用,可能取决于下游任务。例如,对于事件驱动的语言使用变化与任务性能无关的任务,它可能不太有用[101]。
重要性:时间适应对于问答尤其重要,因为问题的答案可能会根据提出问题的时间而改变[102] [103]。
预测:开发能够适应新时间框架的方法需要摆脱静态的预训练微调设置,并且需要有效的方法来更新预训练模型的知识。在这方面,有效的方法(Efficient Methods)和检索增强(Retrieval Augmentation)都是有用的。还需要开发一些模型,这些模型的输入并不存在,而是建立在语言外语境和现实世界的基础上。有关此主题的更多工作,请查看 EMNLP 2022 的 EvoNLP 研讨会。
14)The Importance of Data

An example from MaRVL related to the Swahili concept leso ("handkerchief"), which requires models to identify whether the description in the caption is true or false. The caption (in Swahili) is: Picha moja ina watu kadhaa waliovaa leso na picha nyingine ina leso bila watu. ("One picture contains several people wearing handkerchiefs and another picture has a handkerchief without people."). The label is false (Liu et al., 2021).
进展:长期以来,数据一直是 ML 的关键要素,但通常被建模的进步所掩盖。然而,鉴于数据对于扩大模型的重要性,注意力正慢慢从以模型为中心的方法转移到以数据为中心的方法。重要主题包括如何有效地构建和维护新数据集以及如何确保数据质量(有关概述,请参阅NeurIPS 2021 上以数据为中心的 AI 研讨会)。特别是,预训练模型使用的大规模数据集今年受到审查,包括多模态数据集[104]以及英语和多语言文本语料库[105] [106]。这样的分析可以为设计更具代表性的资源提供信息,例如 MaRVL [107]用于多模态推理。
重要性:数据对于训练大规模 ML 模型至关重要,也是模型如何获取新信息的关键因素。随着模型的扩大,确保大规模数据质量变得更具挑战性。
预测:我们目前缺乏关于如何有效地为不同任务构建数据集、可靠地确保数据质量等方面的最佳实践和原则性方法。对于数据如何与模型的学习交互以及数据如何塑造模型的偏差也知之甚少。例如,训练数据过滤(training data filtering)可能会对语言模型对边缘化群体的覆盖产生负面影响[90:1]。
15)Meta-learning

The training and test setup of the universal template model. A model consisting of shared convolutional weights and dataset-specific FiLM layers is trained in a multi-task setting (left). FiLM parameter values for a test episode are initialized based on a convex combination of the trained sets of FiLM parameters, learned on the training data (right). They are then updated using gradient descent on the support set, with a nearest-centroid classifier as the output layer (Triantafillou et al., 2021).
进展:尽管元学习和迁移学习在少样本学习中有着共同的目标,但主要是在不同的社区中进行研究。在一个新的基准[108]上,大规模迁移学习方法优于基于元学习的方法。一个有希望的方向是扩大元学习方法,结合更高效的内存训练方法,可以提高元学习模型在现实世界基准测试中的性能[109]。元学习方法也可以与有效的适应方法(Efficient Methods)(比如 FiLM layers[110])相结合,以有效地使通用模型适应新的数据集[111]。
重要性:元学习是一种重要的范式,但在设计standard benchmarks时并未考虑元学习,因而使其未能产生state-of-the-art results。将元学习和迁移学习社区更紧密地联系在一起可能会产生在实际应用中更实用的元学习方法。
预测:当与可用于大规模多任务学习(massive multi-task learning)的大量任务相结合时,元学习可能特别有用。元学习还可以用来改善prompting,即根据大量可用的prompts,学习如何设计或者使用提示。
博客原文链接:
ML and NLP Research Highlights of 2021
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢