
OpenAI本周宣布了GPT-3的Text and Code Embeddings(论文),据称几个相关任务达到SOTA性能。但Hugging Face研究科学家Nils Reimers在研究后得到的结论是:
- 虽然他对OpenAI的新版本很兴奋,但结果并不如预期;
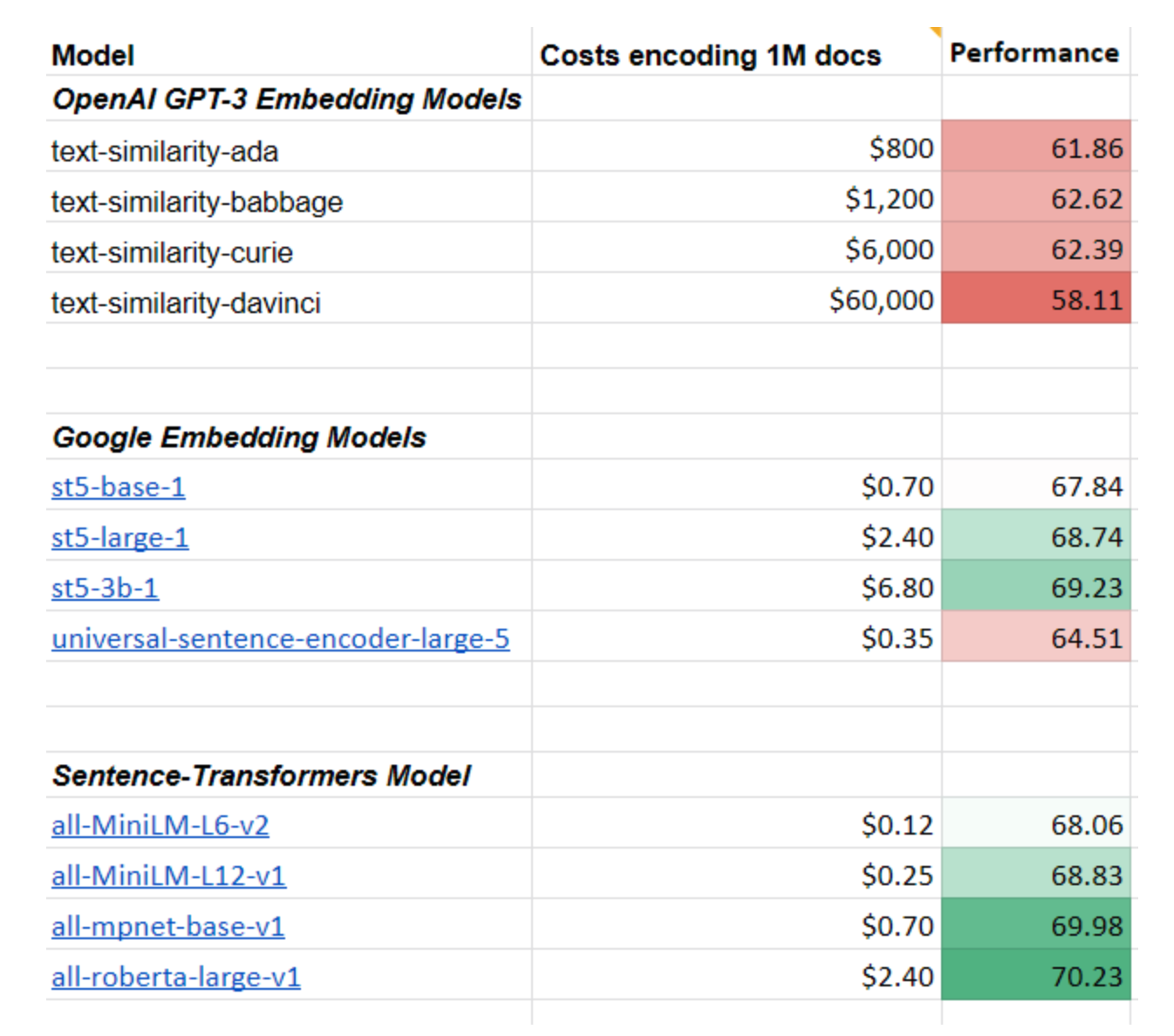
- OpenAI的文本相似性模型表现很差,比目前的技术水平(all-mpnet-base-v2 / all-roberta-large-v1)差很多。事实上,表现比2018年的模型(如 Universal Sentence Encoder)还差。比能在浏览器运行的22M参数的极小模型还弱6分;
- 文本搜索模型表现相当好,在几个基准上给出了良好的结果。但与最近免费提供的模型相比,还不是很先进;
- 又慢又贵:用最小的OpenAI模型对1000万份文件进行编码将花费大约8万美元。相比之下,使用同样强大的开放模型并在云端运行,成本将低至1美元。为一个每月有100万次查询的应用程序使用OpenAI模型,成本高达9,000美元/月。用开放模型,在更低的延迟下表现更好,对于同样的使用情况,每月只需要300美元。
- 模型产生了极高维度的嵌入,大大降低了下游应用的速度,同时需要更多内存。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢