
作者:Shaden Smith, Mostofa Patwary, Brandon Norick, 等
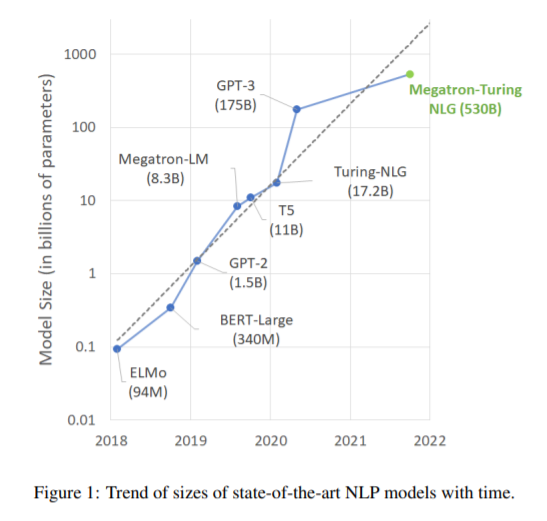
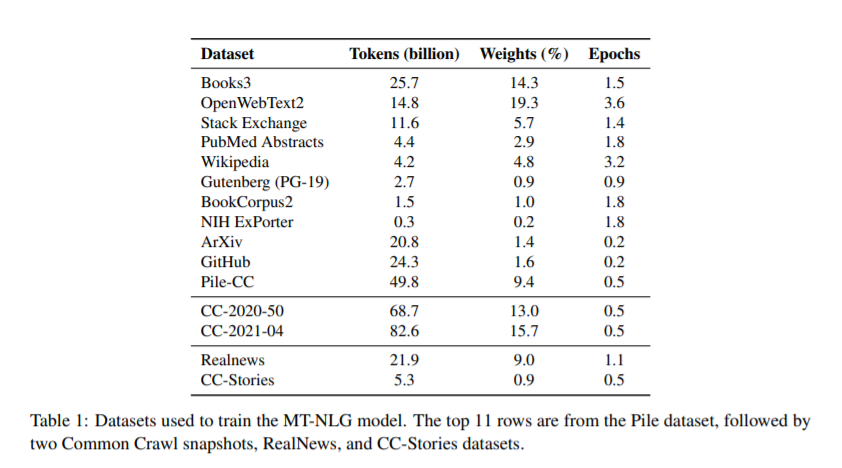
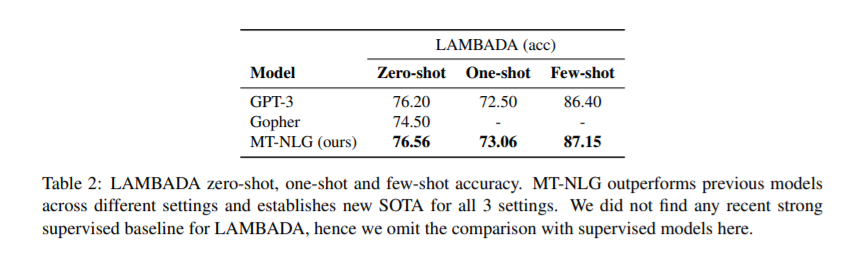
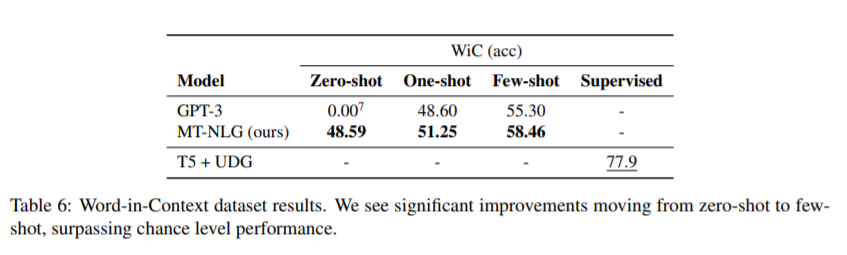
简介:经过预训练的通用语言模型可以通过零触发、少触发和微调技术来适应下游任务,从而在各种自然语言处理领域实现最先进的精度。由于上述的成功,相关模型的规模迅速增加,导致需要高性能的硬件、软件和算法技术才能训练如此大的模型。作为微软和NVIDIA共同努力的结果,作者介绍了最大的基于单transformer 的语言模型Megatron-Turing NLG 530B(MT-NLG)的训练细节,该模型具有5300亿个参数。在本文中,作者首先聚焦于使用DeepSpeed和Megatron来训练该模型的基础设施以及3D并行方法。然后详细介绍了训练过程、训练语料库的设计和数据整理技术,作者认为这是该模型成功的关键因素。最后,作者讨论了各种评估结果以及MT-NLG显示的其他有趣的观察结果和新特性。作者证明了MT-NLG在多个NLP基准上实现了优异的零、一和少样本学习精度,并斩获了新的最先进的结果。作者相信本文的贡献将有助于进一步发展大规模训练基础设施、大规模语言模型和自然语言时代。
论文下载:https://arxiv.org/pdf/2201.11990.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢