
在本文中,作者提出了VideoCLIP,这是一种不需要下游任务的任何标签,用于预训练零样本视频和文本理解模型的对比学习方法。VideoCLIP通过对比时间重叠的正视频文本对 和最近邻检索的负样本对 ,训练视频和文本的Transformer。
在本文中,作者对一系列下游任务(包括序列级文本视频检索、VideoQA、token级动作定位和动作分割)进行了实验,实验结果表明本文提出的VideoCLIP可以达到SOTA的性能,在某些情况下甚至优于监督方法。

论文地址:
https://arxiv.org/pdf/2109.14084.pdf
代码地址:
https://github.com/pytorch/fairseq/tree/main/examples/MMPT
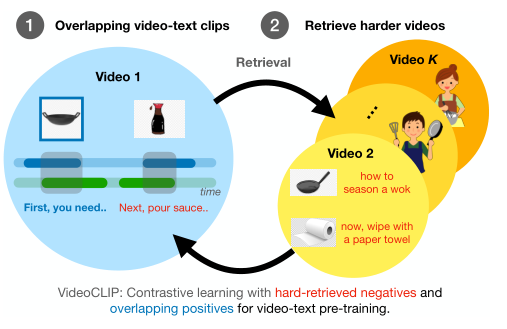
在本文中,作者提出了VideoCLIP,使用了两种关键技术(如上图所示)来计算训练目标,通过对比学习来预训练统一的视频文本表示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢