标题:Meta|Few-shot Learning with Multilingual Language Models(多语言模型的小样本学习)
作者:Xi Victoria Lin, Xian Li等
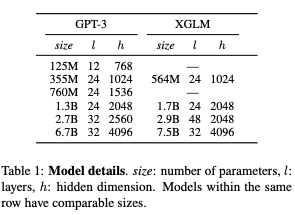
简介:本文介绍了多语言模型的零样本泛化性能。像GPT-3这样的大规模自回归语言模型,小样本学习器可以无需微调即可执行广泛的语言任务。虽然这些模型是已知能够联合表示许多不同的语言,他们的训练数据以英语为主,这可能会限制他们跨语言泛化。在这项工作中,作者在涵盖多种语言的平衡语料库上训练多语言自回归语言建立模型,并研究它们的少数和广泛的零样本学习能力的任务。作者最大的模型拥有75亿个参数,在少数情况下创造了新的技术水平学习超过20种代表性语言,表现优于可比的GPT-3多语言常识推理中的大小(零样本绝对精度提高 +7.4%,四样本+9.4%)和自然语言推理(+5.4%在零样本和四样本设置中)。在FLORES-101机器翻译基准,作者的模型在GPT-3在32个训练示例的182个翻译方向中171上有优势,同时在 45个方向上超过了官方监督基线。作者提出对模型成功和失败的地方进行详细分析,特别表明它实现跨语言的上下文学习一些任务,而在表面形状的鲁棒性和没有自然规律的任务完形填空形式等适应性上存在不足。最后,作者评估模型社会价值任务,例如 5 种语言的仇恨言论检测,并发现它类似于同等大小型号GPT-3有局限性。
代码下载:https://github.com/pytorch/fairseq/tree/main/examples/xglm
论文下载:https://arxiv.org/pdf/2112.10668.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢