标题:OpenAI|Text and Code Embeddings by Contrastive Pre-Training(通过对比预训练进行文本和代码嵌入)
作者:Arvind Neelakantan, Tao Xu, Lilian Weng等
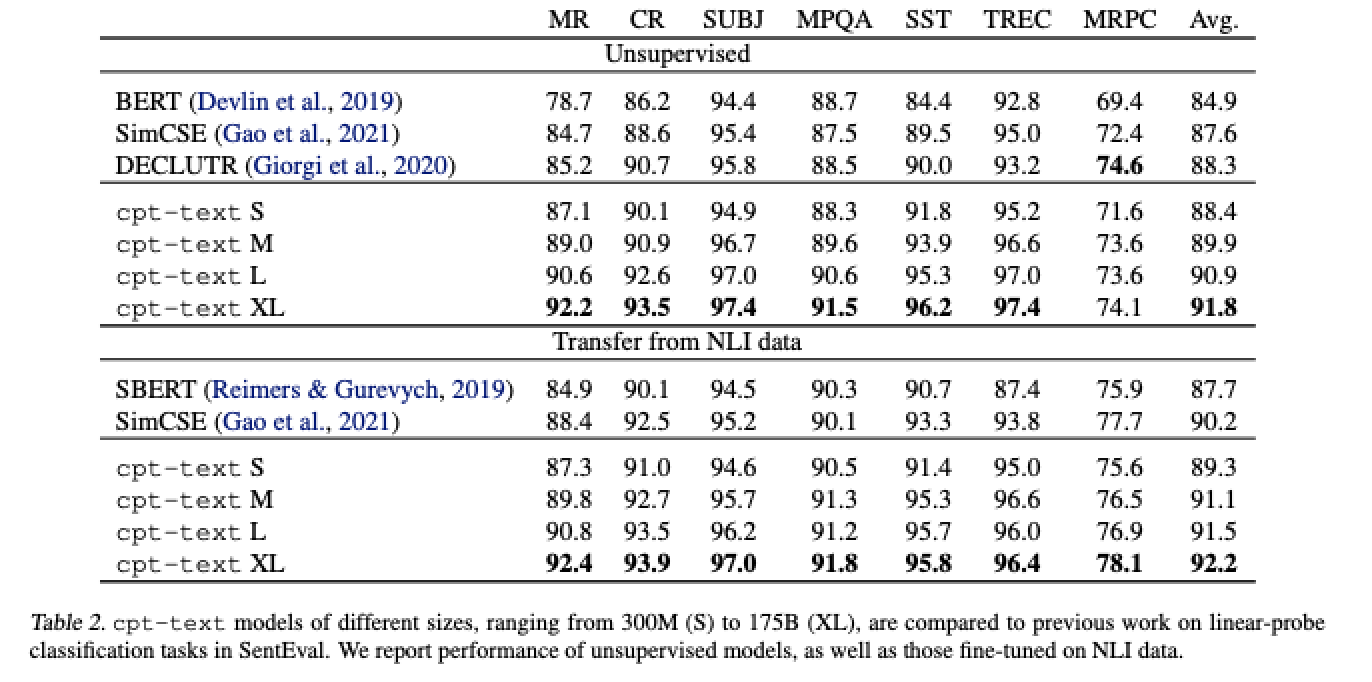
简介:本文介绍了将GPT-3用于文本表示方法。文本嵌入用于功能语义搜索和计算文本相似度等应用。以前的工作通常训练针对不同用例定制的模型,不同的数据集选择、训练目标和模型架构。在这项工作中,作者表明在无监督数据上进行对比预训练规模导致高质量的向量表示的文本和代码。相同的无监督文本嵌入实现了新的最先进的结果,在线性探针分类中也显示出令人印象深刻的语义搜索能力,有时甚至可以与微调模型竞争。在平均超过 7 个任务的线性探针分类精度上,作者最好的无监督模型实现了 4% 和 1.8% 的相对改善,超过以前最好的无监督和有监督文本嵌入模型。相同大规模评估时的文本嵌入语义搜索获得了相对的改进23.4%、14.7% 和 10.6%,比之前的最高水平MSMARCO、Natural上的无监督方法分别是问题和TriviaQA基准。与文本嵌入类似,作者训练(文本,代码)对上的代码嵌入模型,相对于之前的代码搜索的最佳工作改进了20.8%。
论文下载:https://cdn.openai.com/papers/Text_and_Code_Embeddings_by_Contrastive_Pre_Training.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢