近日,深度学习国际顶级会议ICLR 2022向作者公布了论文录用结果。香侬科技与浙江大学、新加坡南洋理工大学等单位合作提出的基于图神经网络的语义理解模型GNN-LM获得了单项评审满分(10分)。
论文链接:
https://arxiv.org/abs/2110.08743
代码链接:
https://github.com/ShannonAI/GNN-LM
如今大多数NLP模型可以认为是遵循闭卷考试模型:在标注数据集上,模型训练N个epoch, 可以比作学生看了N遍书,然后把他们“背”下来。在测试的时候,学生需要把书合上,不允许再去参考训练数据。 这种闭卷考试策略有两个局限性:一是基于记忆的很难记住训练集中长尾的例子,二是记忆整个训练数据所需的存储空间过大。
本文提出了一个全新的语义理解模式,将闭卷考试转化为开卷考试的语义理解模式:在测试的时候,模型允许参考训练数据。这样就将之前的“背”,转变成了“抄”,模型可以直接使用训练集中相关的例子来协助决策,这样问题的难度就大大降低了。以语言模型来举例,例如,给定前文“J.K.罗琳最知名的作品是”来预测后面的词“哈利波特”,如果语言模型可以引用训练集中相关的上下文“J.K.罗琳撰写了哈利波特系列书籍”,那么它就会更容易将下一个token预测为“哈利”,就像是有参考书的开卷考试比闭卷考试要更简单一样。
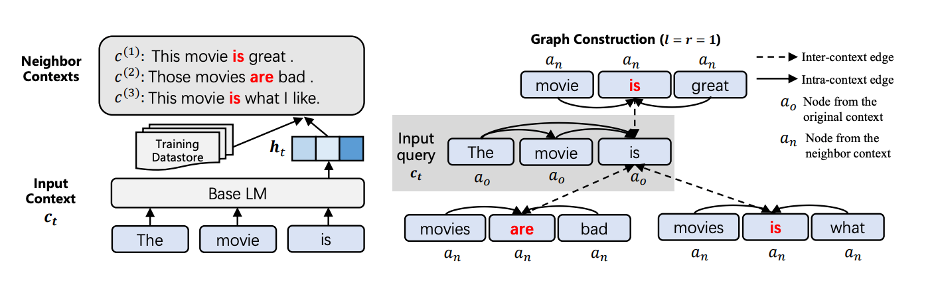
基于这一认识,本文提出了基于图神经网络的语义理解模型的GNN-LM,它将传统的NLP的闭卷模式,转变为开卷模式:在推理过程中允许参考训练数据。模型首先以输入的样例为query,首先在训练数据中通过K近邻(KNN)寻找相似的样例为邻居。找到了相似的邻居之后,我们需要考虑不同的邻居不同的影响,有的影响更大,有的影响更小。为了自动学习这些不同的影响,我们通过图神经网络GNN建立输入样例与邻居的关系。换言之,输入样例的表征基于输入样例与邻居通过GNN得到。如下图所示,我们想预测 “The movie is”后面即将出现的词,我们用“The movie is”作为query, 找到数据中相似的邻居,其中包括“This movie is great”, “Those movies are bad” 以及 “The movie is what I like”。我们将这四句话建立起一个图结构:“The movie is” 中的 “movie” 与其他近邻中的 “movie”建立边,“is” 与其他近邻中的 “is”建立边。然后通过GNN得到表征。参考这些相似的例子,得到预测结果。
实验表明,该方法提出的GNN-LM框架使基础LM有了显著的性能提升,在三个广泛使用的语言模型数据集性能达到SOTA结果。内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢